肇事人的事故记录在这 => 一次 MySQL 差点爆了的事故,本文为事后复盘。
前言
上周接到通知,要进行 2024 年度“十佳大学生”和“示范班级”线上投票,投票程序要求如下:
- 投票时间:12 月 11 日 00:00-12 月 13 日 23:59
- 可投票人员:校内师生
- 投票规则:每人每天有一次投票机会,每一票需投满 10 个候选人
上届使用的是问卷网,但无法满足对投票人员(校内师生)的限制,正好今年精弘内部的问卷系统已经投入使用,于是决定基于此进行投票业务的拓展,同时接入学校统一身份认证系统,以满足需求。
12.10 23:06 更新完的系统经过内部测试后上线生产环境。
12.11 00:00 开始有零星人员投票,系统无异常,各岗位下班。
异常发现
12:01 前端负责同学发现获取投票数据接口出现超时问题,错误反馈如下图(timeout of 10000ms exceeded),即对后端的请求+响应时间超过了 request.js 设置的 10s 超时时间。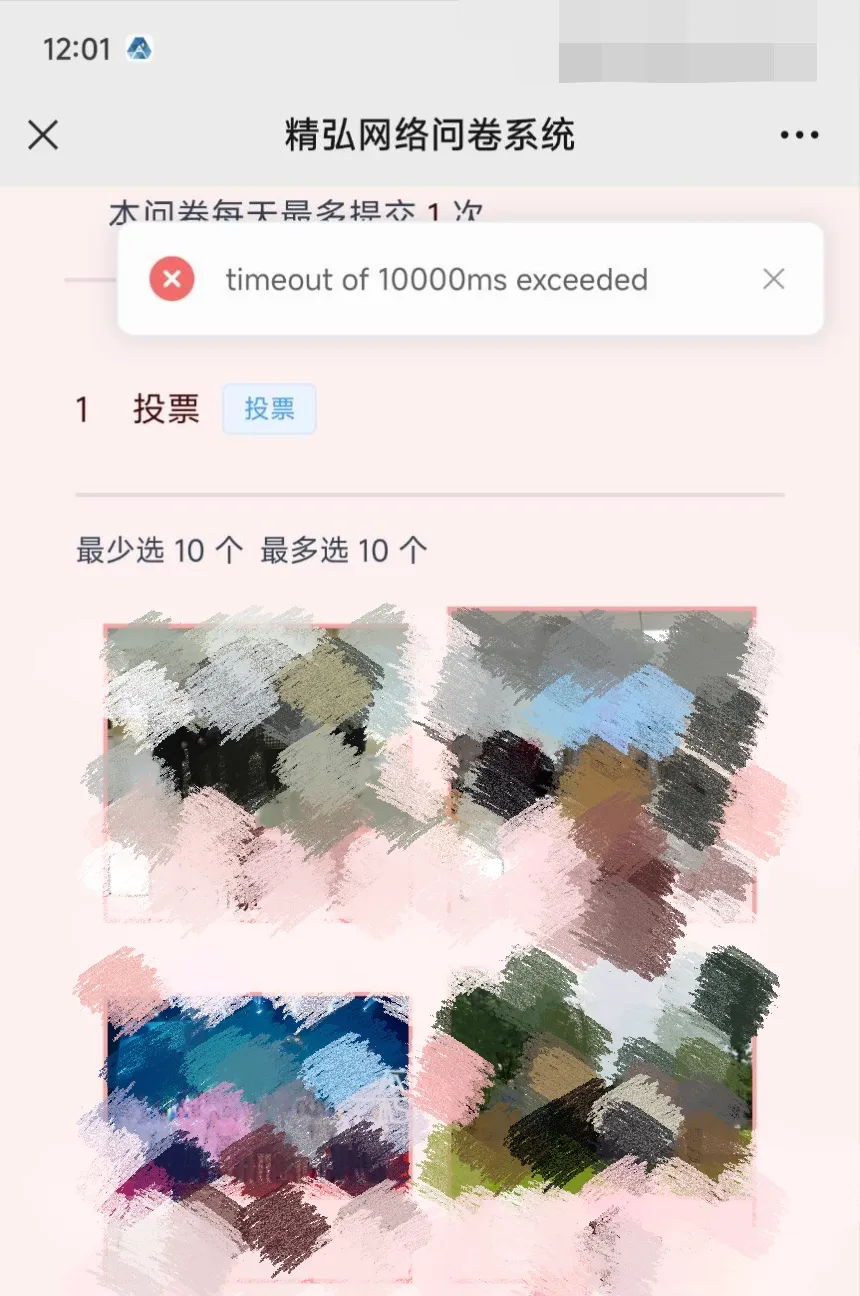
具体影响为票数结果和排名无显示或延迟显示,可见下图对比:
- 正常情况
- 超时情况


12:17 接到熟人反馈。
12:30 后端负责同学经过日志和初步测试,发现该接口平均响应时间达到了 7s 以上。
12:42 部门老员工发现服务器中 MySQL 的CPU 使用率变化幅度极大,峰值 CPU 打满了 2 个核达到了 200% ,可见下图:
- 低谷

- 峰值

由于担心 MySQL 的 CPU 占用长时间过高被系统 kill,带着微精弘的服务一起挂掉,开始紧急排查。
根因定位
根据日志和后台首先可以排除 QPS 的并发问题,毕竟这是投票业务而非抢票业务,实际上精弘毅行的抢票也没有达到如此高的 CPU 占用,于是怀疑是接口中的 SQL 调用问题。结合之前的超时情况,基本可以直接定位到获取投票数据接口。
对该接口的业务代码进行分析后,果然找到了导致 MySQL 高占用的根因。下图是相关的代码,这边先抛开业务逻辑,可以看到框出的两行代码嵌入在一个大循环里面。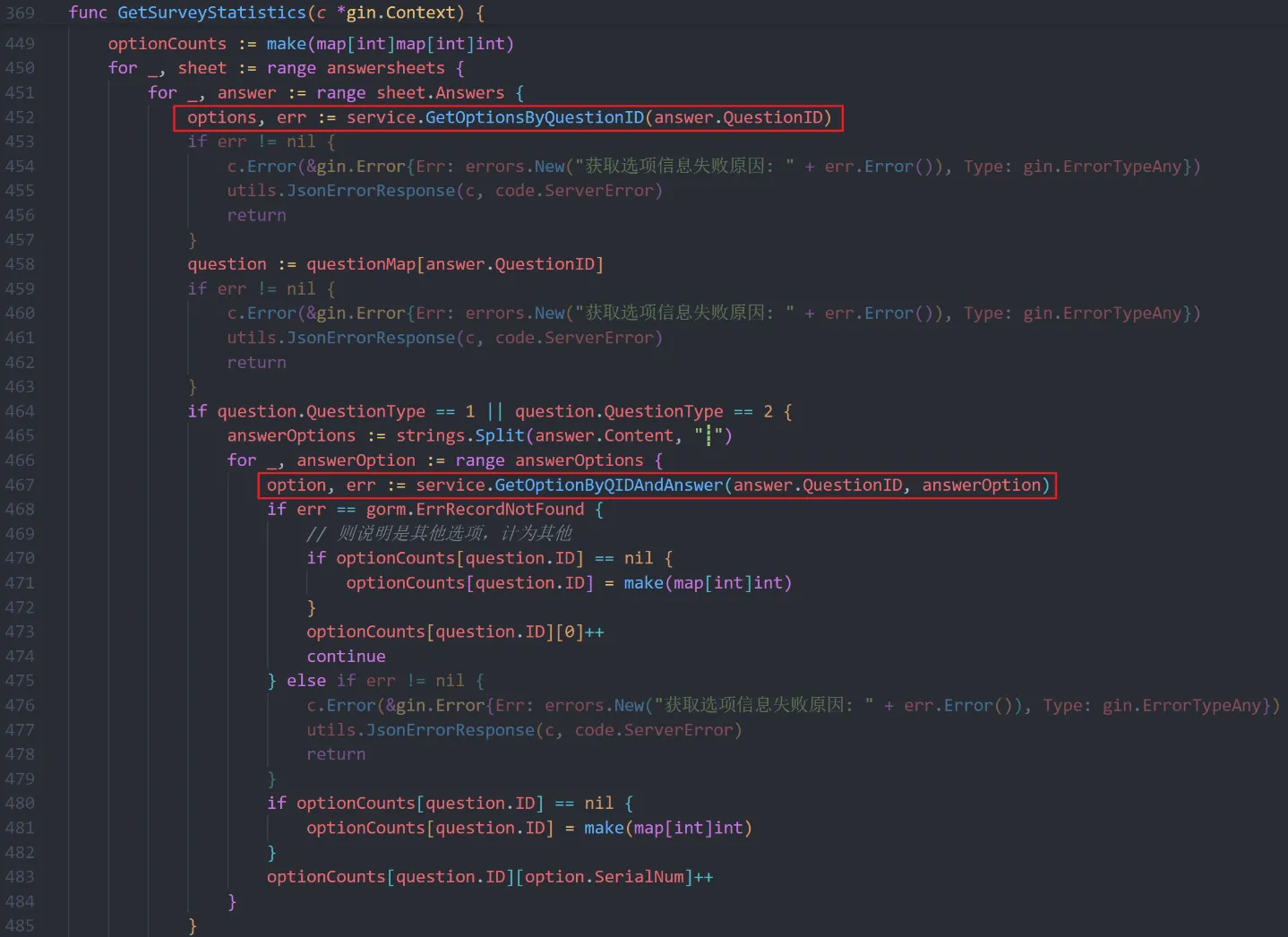
而这两行代码都各自对应着一条查询的 SQL,如下图所示,SQL 很简单,但是叠加上 O(N^3) 的循环,直接导致在短时间内有大量 SQL 打入数据库,引起 CPU 的激增。
原因分析
重新梳理一下业务处理逻辑,该接口用于投票数据统计,采取的方案是简单粗暴的循环遍历,其整体流程如下(已简化):
- 第一层循环
for _, sheet := range answerSheetsanswerSheets代表的是所有的投票答卷信息,每份sheet中包含的信息可参考下图,该循环所代表的是遍历每个人的 AnswerSheet(投票答卷),有几份答卷此处就循环几次
- 第二层循环
for _, answer := range sheet.Answerssheet.Answers中包含的信息同样可参考上图,该循环代表遍历投票答卷中的所有 Question(问题),有几个问题此处就循环几次- 从 MySQL 中查询问题(都是选择题型)的所有 Option(选项)
if question.QuestionType == 1 || question.QuestionType == 2,这里type的 1 和 2 分别代表单选题和多选题answerOptions := strings.Split(answer.Content, "┋"),多选题的Answer(回答) 记录方式是option1┋option2┋option3,因此使用 Split 分割 ┋ 获取答卷选择的选项
- 第三层循环
for _, answerOption := range answerOptions- 即遍历答卷问题所选择的所有选项,选几个选项此处就循环几次
- 从 MySQL 中查询
answerOption对应的选项,包含信息如下图所示: 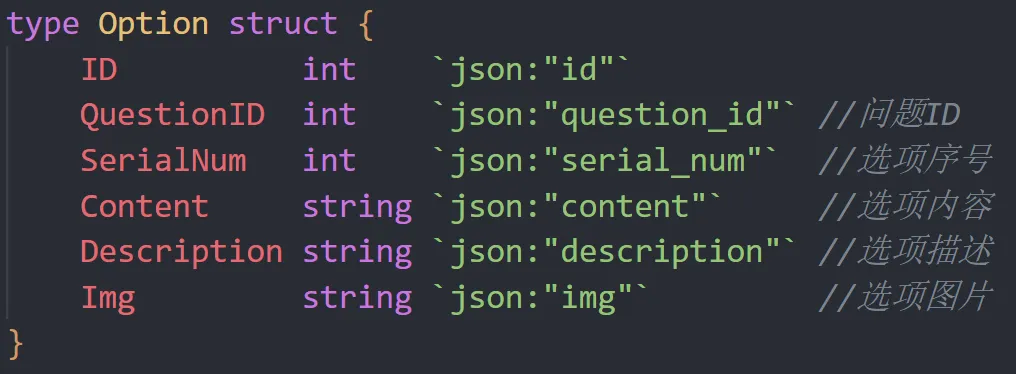
- 在
optionCounts的 map 中根据选项中的QuestionID和SerialNum开始计数,以实现统计各个问题中各个选项的票数
上面进行的分析,是为了方便理解下面的计算。十佳投票截止 12:00 共收集到 715 份答卷,仅计算循环内,从每一个获取投票数据接口的请求进来开始,会查询 MySQL 共 715*1*(1+10)=7865 次。
- 715 是第一个循环的投票答卷数
- 第一个 1 是第二个循环的问题个数,此处十佳投票仅 1 个问题
- 第二个 1 是第二个循环下
GetOptionsByQuestionID的 SQL 查询执行次数 - 10 是第三个循环的答卷选项个数,此处十佳投票限制每次需投 10 票,也代表
GetOptionByQIDAndAnswer的 SQL 查询执行次数
同时该数据会随投票人数的增多而不断增长,保守预计最后的答卷至少会破 2000 份,也就是说最后 MySQL 会迎来 2w 级的 TPS。
初步优化
为了防止 MySQL 真的被 kill 掉或者服务器崩盘,临时准备将获取投票数据的接口降级(即 ban 掉该接口),因为投票的核心业务在投票,是否能查看到该投票数据本身的影响并不大。
不过该业务的负责人亡羊补牢,给出了临时优化方案:将高频读取的数据存储到 Redis(高性能的内存数据库) 中进行缓存。
在查询 MySQL 前先查询 Redis 缓存中是否存在,若存在(即命中)则直接从 Redis 返回数据,若不存在则查询 MySQL 后先将数据更新至 Redis 缓存中再返回,流程图可参考如下: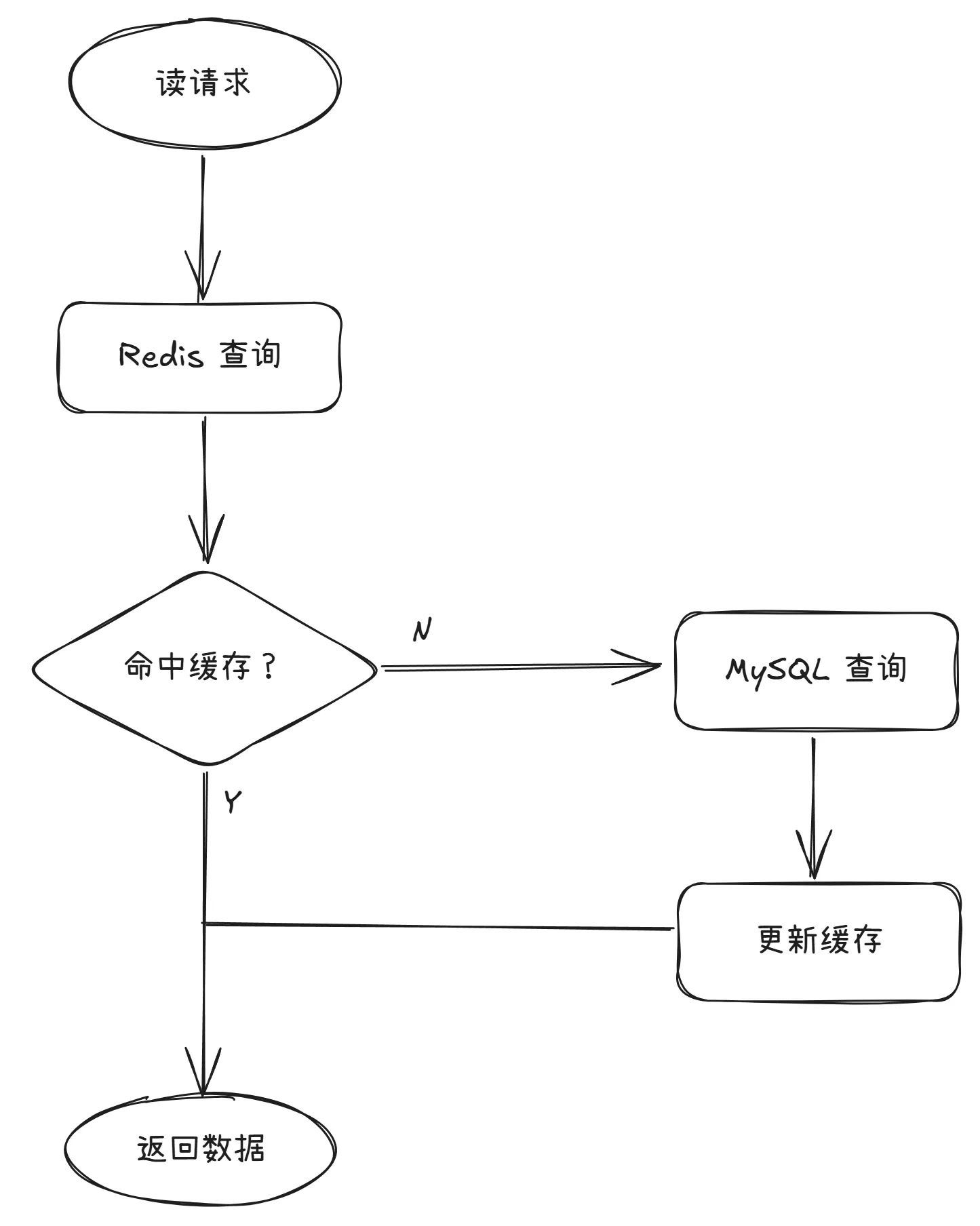
等价于将循环内的请求都从 MySQL 转到了 Redis,对于 Redis 而言哪怕是 2w 级 TPS 也在承受范围之内。
14:28 后端负责人给出了初步优化代码,代码如下: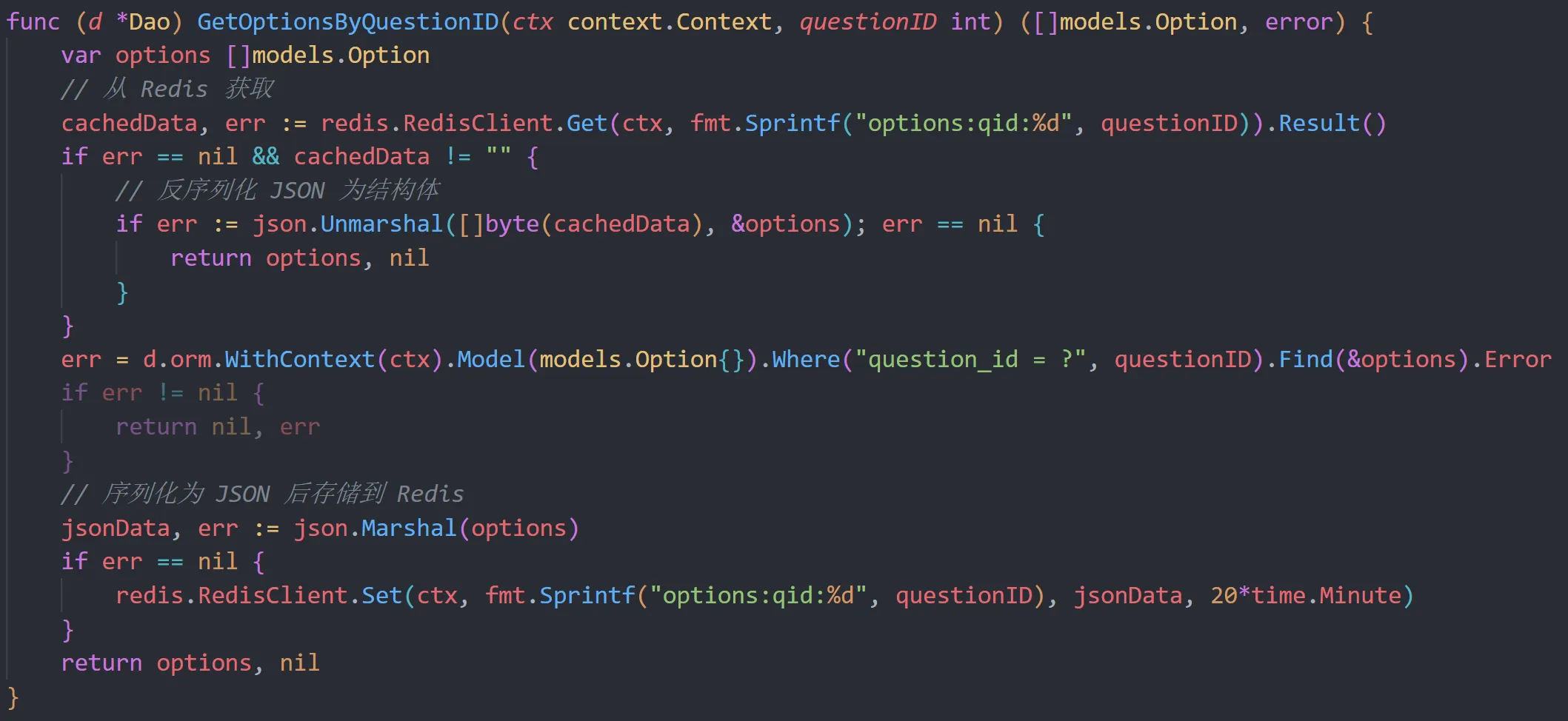
14:38 测试无误后上线生产环境,优化后情况如下:

- 峰值 CPU 使用率大幅度降低
- MySQL CPU 使用率回到正常水平
- 接口响应时间降低至 800ms 内

不过代价是 Redis 的 CPU 使用率开始增加,不过在可控范围之内。
进一步优化
燃眉之急已经解决,但是依然有较高的 CPU 波动存在,以及依旧会随着投票人数的增多进行上涨。
进一步优化的方法其实也很简单,因为实际上查询的数据都是重复的,完全可以在进入循环之前通过内存数据结构(如 map),将原先循环中 GetOptionsByQuestionID 和 GetOptionByQIDAndAnswer 的结果一次性加载到内存中,避免对 Redis 或 MySQL 的大量请求以及造成的不必要开销。
优化后的代码如下(部分):
1 | func GetSurveyStatistics(c *gin.Context) { |
结合初步优化,原先循环中对 MySQL 的大量查询 SQL已经优化为 1 次对 Redis 的查询(即问题选项的查询,此处十佳的问题只有一个),且不随投票人数增长。
12.12 00:00 更新生产环境,此次优化后的情况如下:

- CPU 回归正常水平,无较大波动
- 接口响应时间降低至 20ms 左右

后续优化方案
虽然问题目前已经解决,但是在事后的复盘和讨论当中,认为原处理方案依旧有些繁琐和暴力,也不够优雅,不过在某种意义上也秉持了先上线后优化的原则。
- 后续优化方案
- 在用户投票完将答卷记录在 MongoDB 上后(由于问卷题目和题型的自定义特性,采用文档数据库存储答卷信息),在 Redis 中同步记录各个选项的票数,但需要保证操作的原子性
- 如何获取投票数据
- 直接从 Redis 中读取,无须再次统计
- 优点
- 可以避免从 MongoDB 中获取所有投票答卷的开销
- 可以直接优化掉原方案中统计所需要的 O(N^3) 循环
- 对于大量投票答卷数据依旧能做到快速响应
总结
补一张当天服务器 CPU 利用率的监控数据: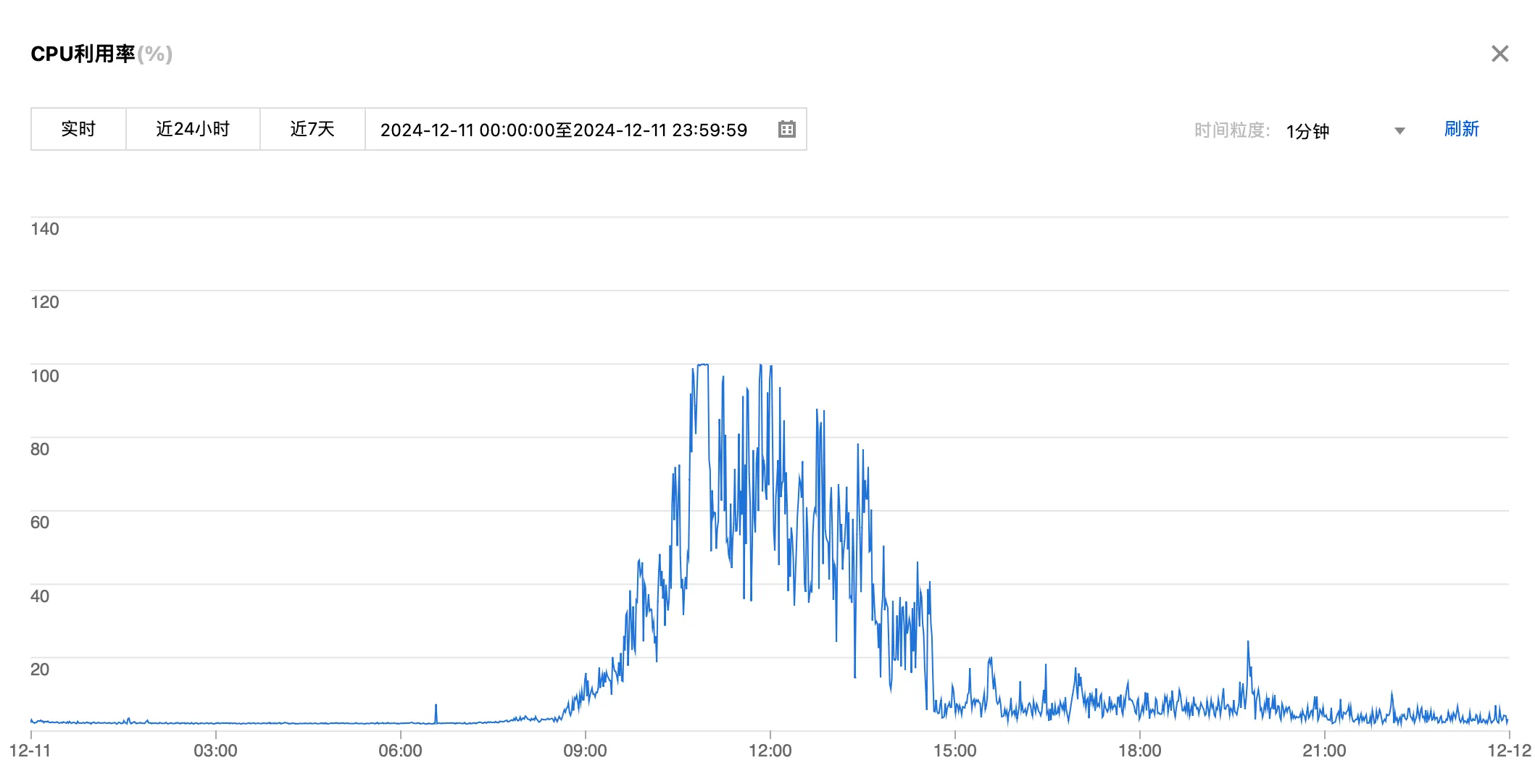
虽然没有出现系统崩溃的情况,但依然可以算是一次不小的生产事故,事后当晚专门拉了批斗会复盘会,这边就以后端负责同学的反思作为本次事故的总结:
- 代码质量
- 复用代码时缺乏充分的审查,直接上线导致了生产事故,需遵循 代码审查规范,即使是复用代码也要彻底理解逻辑
- 测试预警
- 在部署前应模拟场景测试接口性能,并通过大批量数据测试发现潜在瓶颈。
- 团队协作
- 提前与团队沟通,充分利用同学的建议和经验来改进代码(如这次的 map 优化建议)。
- 生产环境监控
- 做好对应系统的安全负责人,持续关注发布后的生产环境的日志和性能指标,及时发现潜在问题。
- 服务降级机制
- 对于不影响核心功能的模块(如此次的获取投票数据接口),可实现服务降级处理,以保证主要功能的正常运行。
- 沟通与决策
- 及时在工作群暴露问题,在处理问题时需与技术总监充分沟通,明确处理方案,并且须经充分测试,确保安全无误后才投入生产环境。
最后以后端同学请了一人一杯奶茶作结。
写在最后
如果对于精弘问卷系统有问题或者建议,欢迎来提 issue。

