经典案例
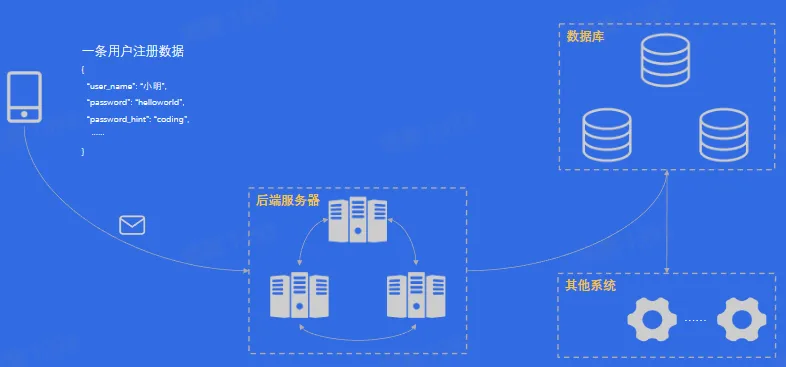
- 数据的产生
- 数据的流动
- 数据的持久化
- 潜在的问题
- 数据库怎么保证数据不丢
- 数据库怎么处理多人同时修改的问题
- 为什么用数据库,除了数据库还能存到别的存储系统吗
- 数据库只能处理结构化数据吗
- 有哪些操作数据库的方式,要用什么编程语言


存储 & 数据库简介
存储系统
- 系统概览
- 什么是存储系统?
- 一个提供了读写、控制类的接口,能够安全有效的把数据持久化的软件,就可以称为存储系统

- 系统特点
- 作为后端软件的底座,性能敏感
- 存储系统软件架构,容易受硬件影响
- 存储系统代码,既“简单”又“复杂”
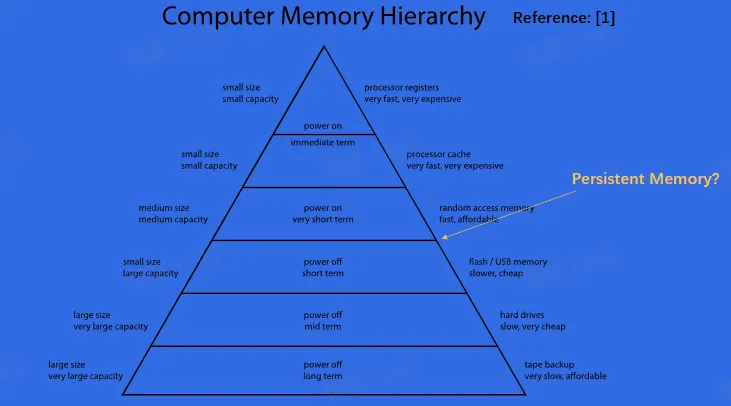
- 存储器层级结构
- 数据怎么从应用到存储介质
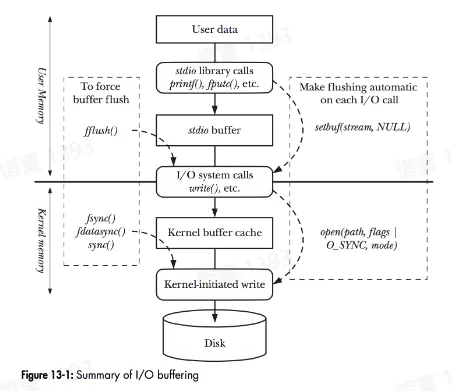
- [缓存] 很重要,贯穿整个存储体系
- [拷贝] 很昂贵,应该尽量减少
- 硬件设备五花八门,需要有抽象统一的接入层
- RAID 技术
- 单机存储系统怎么做到高性能/高性价比/高可靠性?
- R(edundant) A(rray) of I(nexpensive) D(isks)
- RAID 出现的背景:
- 单块大容量磁盘的价格>多块小容量磁盘
- 单块磁盘的写入性能<多块磁盘的并发写入性能
- 单块磁盘的容错能力有限,不够安全
- RAID 0
- 多块磁盘简单组合
- 数据条带化存储,提高磁盘宽带
- 没有额外的容错设计
- RAID 1
- 一块磁盘对应一块额外镜像盘
- 真实空间利用率仅 50%
- 容错能力强
- RAID 0+1
- 结合了 RAID 0 和 RAID 1
- 真实空间利用率仅 50%
- 容错能力强,写入宽带好
- 单机存储系统怎么做到高性能/高性价比/高可靠性?
数据库
- 数据库和存储系统不一样
- 关系型数据库
- 非关系型数据库
- 概览
- 关系(Relation)是什么?
- Edgar.F.Codd 于 1970 年提出 [关系模型]
- 关系 = 集合 = 任意元素组成的若干有序偶对反映了事物间的联系
- 关系代数 = 对关系作运算的抽象查询语言
- 交、并、笛卡尔积……
- SQL = 一种 DSL = 方便人类阅读的关系代数表达形式
- 关系(Relation)是什么?
- 关系型数据库特点
- 关系型数据库是存储系统,但是在存储之外,又发展出其他能力
- 结构化数据友好
- 支持事务(ACID)
- 支持复杂查询语言
- 关系型数据库是存储系统,但是在存储之外,又发展出其他能力
- 非关系型数据库特点
- 非关系型数据体也是存储系统,但是一般不要求严格的结构化
- 半结构化数据友好
- 可能支持事务(ACID)
- 可能支持复杂查询语言
- 非关系型数据体也是存储系统,但是一般不要求严格的结构化
数据库 vs 经典存储
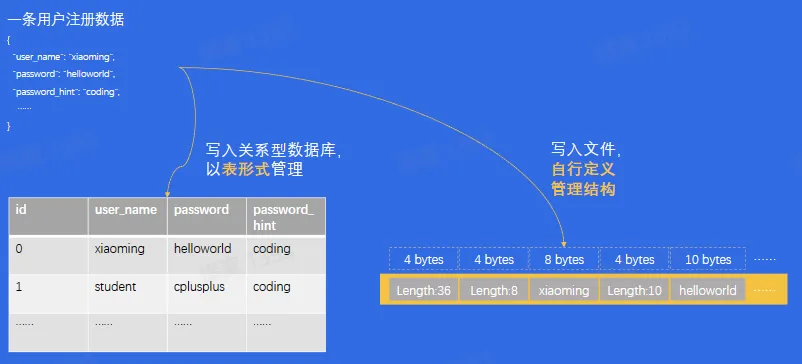
- 结构化数据管理
- 事务能力
- 凸显出数据库支持[事务]的优越性
- 事务具有:
- A(tomicity).事务内的操作要么全做,要么不做
- C(onsistency).事务执行前后,数据状态是一致的
- I(solation).可以隔离多个并发事务,避免影响
- D(urability).事务一旦提交成功,数据保证持久性

- 复杂查询能力
- 写入数据之后,想做很复杂的查询怎么办?
- Example:请查询出名字以 xiao 开头,且密码提示问题小于 10 个字的人,并按性别分组统计人数

数据库使用方式
- Everything is D(omain) S(pecific) L(anguage) ==> maybe SQL
- 以 SQl 为例,要操作数据时,支持以下操作:
- Insert
- Update
- Select
- Delete
- Where 子句
- GroupBy
- OrderBy
- 要对数据库定义做修改时,支持以下操作:
- Create User
- Create database
- Create table
- Alter table
- ……
主流产品剖析
单机存储
- 概览
- 单机存储 = 单个计算机节点上的存储软件系统,一般不涉及网络交互
- 本地文件系统
- key-value 存储
- 单机存储 = 单个计算机节点上的存储软件系统,一般不涉及网络交互
- 本地文件系统
- Linux 经典哲学:一切皆文件
- 文件系统的管理单元:文件
- 文件系统接口:文件系统繁多,如 Ext2/3/4,sysfs,rootfs 等,但都遵循 VFS 的统一抽象接口
- Linux 文件系统的两大数据结构:Index Node & Directory Entry
- Index Node
- 记录文件元数据,如 id、大小、权限、磁盘位置等 inode 是一个文件的唯一标识,会被存储到磁盘上 inode 的总数在格式化文件系统时就固定了
- Directory Entry
- 记录文件名、inode 指针,层级关系(parent)等
- dentry 是内存结构,与 inode 的关系 N:1(hardlink 的实现)
- Index Node
- key-value 存储
- 世间一切皆key-value
- 常见使用方式:put(k,v)&get(k)
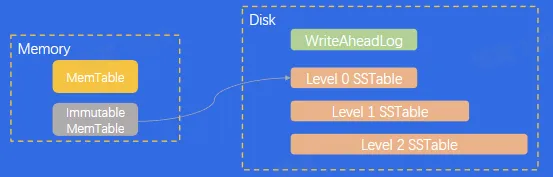
- 常见数据结构:LSM-Tree,某种程度上牺牲读性能,追求写入性能
- 拳头产品:RocksDB
分布式存储
- 概览
- 分布式存储 = 在单机存储基础上实现了分布式协议,涉及大量网络交互
- 分布式文件系统
- 分布式对象存储
- 分布式存储 = 在单机存储基础上实现了分布式协议,涉及大量网络交互
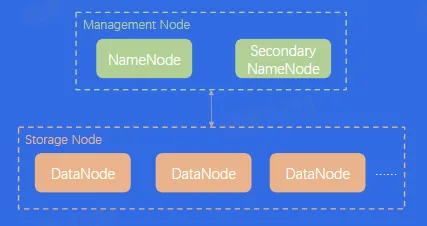
- HDFS
- HDFS:堪称大数据时代的基石
- 时代背景:专用的高级硬件很贵,同时数据存量很大,要求超高吞吐
- HDFS 核心特点:
- 支持海量数据存储
- 高容错性
- 弱 POSIX 语义
- 使用普通 x86 服务器,性价比高
- Ceph
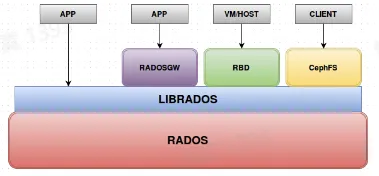
- Ceph:开源分布式存储系统里的 [万金油]
- Ceph 的核心特点:
- 一套系统支持对象接口、块接口、文件接口,但是一切皆对象
- 数据写入采用主备复制模型
- 数据分布模型采用 CRUSH 算法
单机数据库
- 概览
- 单机数据库 = 单个计算机节点上的数据库系统
- 事务在单机内执行,也可能通过网络交互实现分布式事务
- 关系型数据库
- 非关系型数据库
- 关系型数据库
- 商业产品 Oracle 称王,开源产品MySQL & PostgreSQL称霸
- 关系型数据库的通用组件:
- Query Engine——负责解析 query,生成查询计划
- Txn Manager——负责事务并发管理
- Lock Manager——负责锁相关的策略
- Storage Engine——负责组织内存/磁盘数据结构
- Replication——负责主备同步
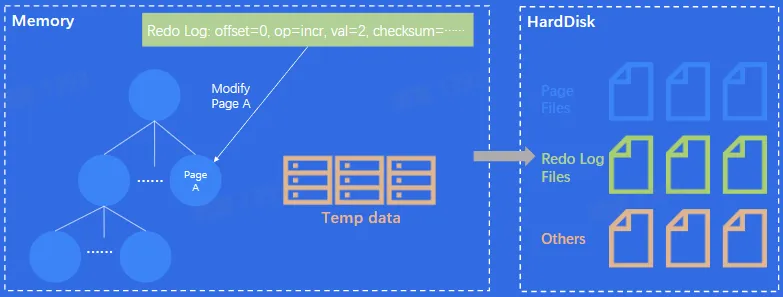
- 关键内存数据结构:B-Tree、B+-Tree、LRU List 等
- 关键磁盘数据结构:WriteAheadLog(RedoLog)、Page
- 非关系型数据库
- MongoDB、Redis、Elasticsearch三足鼎立
- 关系型数据库一般直接使用 SQL 交互,而非关系型数据库交互方式各不相同
- 非关系型数据库的数据结构千奇百怪,没有关系约束后,schema 相对灵活
- 不管是否关系型数据库,大家都在尝试支持SQL(子集)和“事务”

- Elasticsearch 使用案例

分布式数据库
- 从单机到分布式数据库
- 单机数据库遇到了哪些问题 & 挑战,需要我们引入分布式架构来解决?
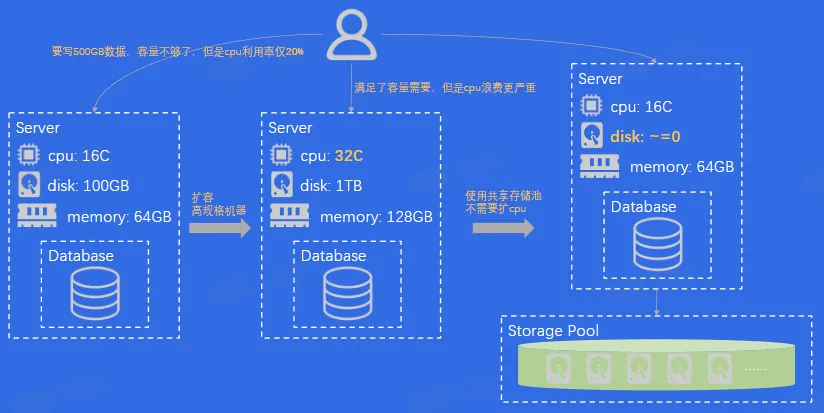
- 容量
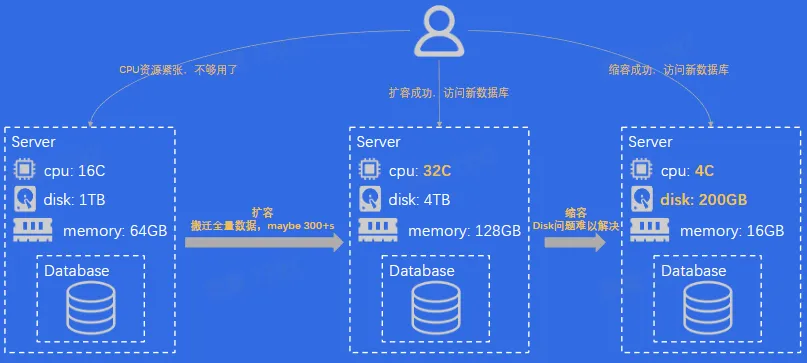
- 弹性
- 性价比
- 单机数据库遇到了哪些问题 & 挑战,需要我们引入分布式架构来解决?
- 解决容量问题
- 解决弹性问题
- 解决性价比问题
- More to Do
- 单写 vs 多写
- 从磁盘弹性到内存弹性
- 分布式事务优化

新技术演进
- 概览
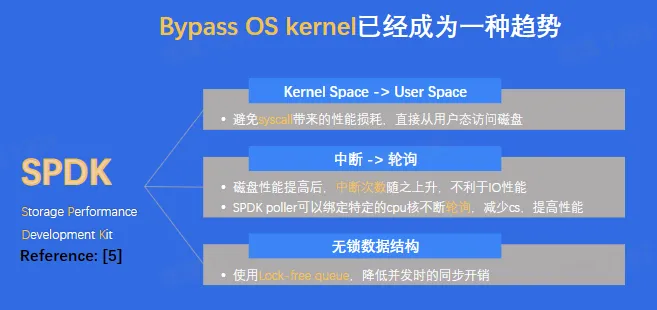
- SPDK
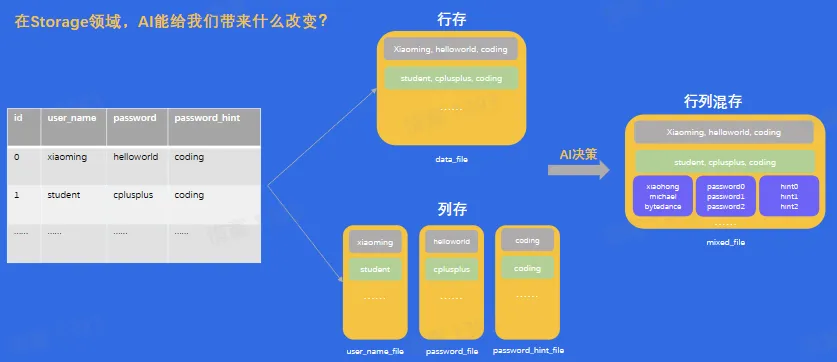
- AI & Storage
- AI 领域相关技术,如 Machine Learning 在很多领域:如推荐、风控、视觉领域证明了有效性
- 高性能硬件


总结


