认识规则引擎
规则引擎的定义
规则引擎是一种嵌入在应用服务中的组件,实现了将业务决策从应用程序代码中分离出来,并使用预定义的语义模块编写业务决策。接受数据输入,解释业务规则,并根据业务规则做出业务决策

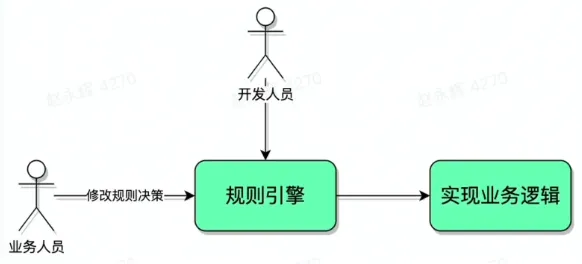
- 解决开发人员重复编码的问题
- 业务决策与服务本身解耦,提高服务的可维护性
- 缩短开发路径,提高效率
组成部分

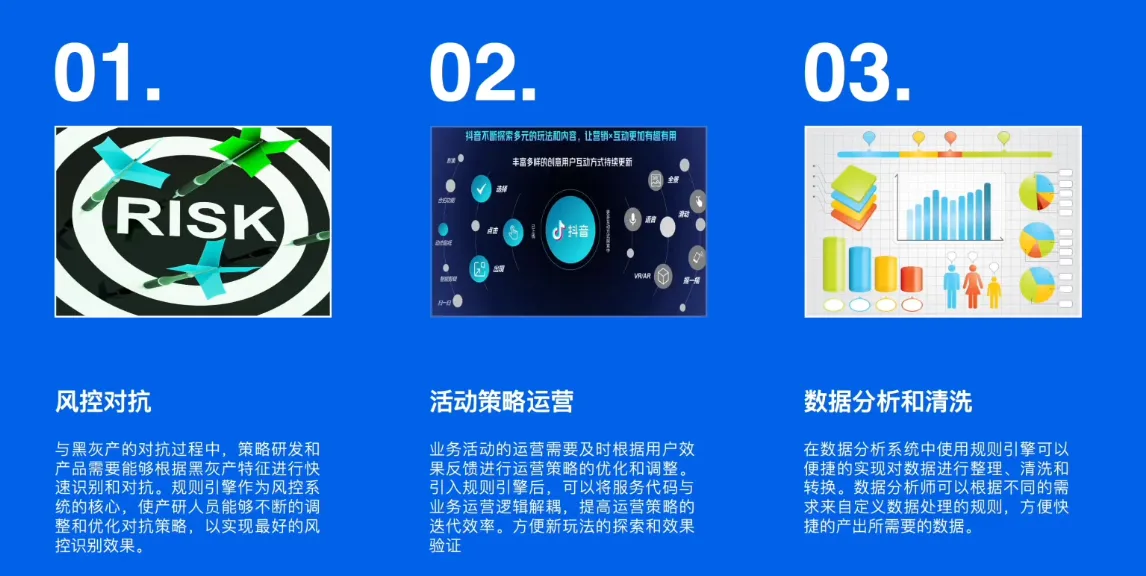
应用场景
编译原理基本概念
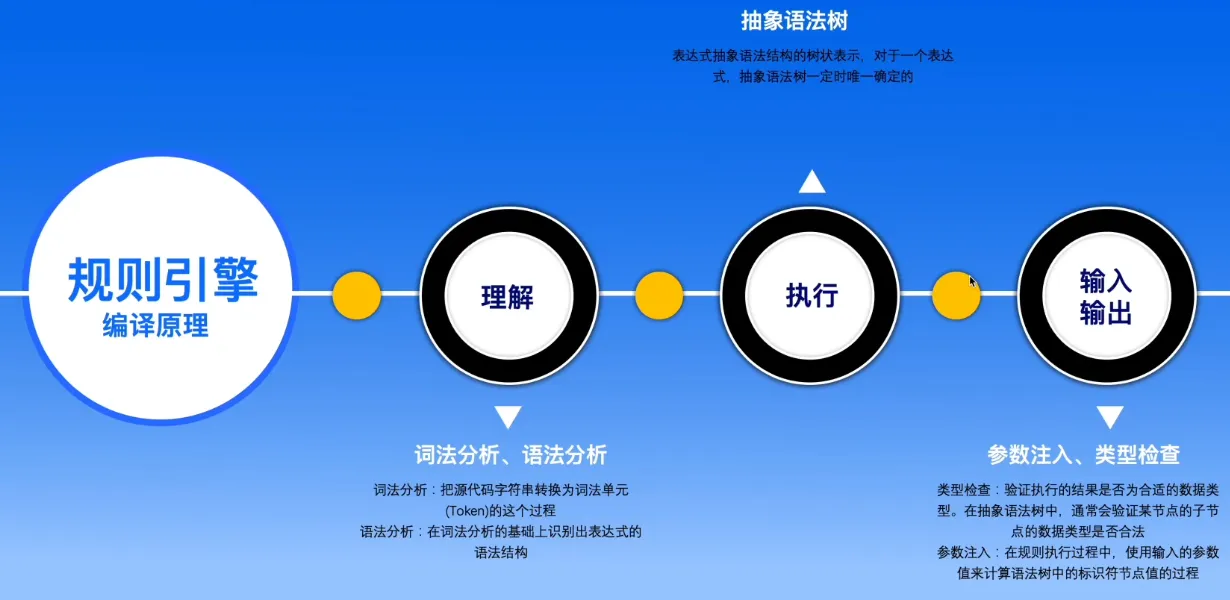
词法分析 Lexical Analysis
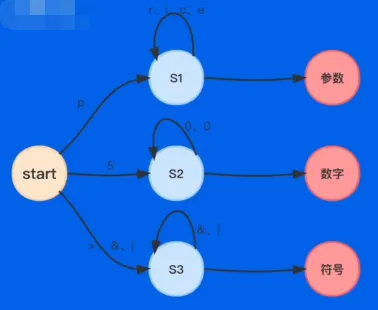
- 词法分析就是把源代码字符串转换为词法单元(Token)的这个过程
- 如何识别 Token?——有限自动机(Finite-State Automation)
- 有限自动机就是一个状态机,它的状态数量是有限的。该状态机在任何一个状态,基于输入的字符,都能做一个确定的状态转换

语法分析 Syntax Analysis
- 语法分析就是在词法分析的基础上,识别表达式的语法结构的过程
- 抽象语法树
- 表达式的语法结构可以用树来表示,其每个节点(子树)是一个语法单元,这个单元的构成规则就叫“语法”。每个节点还可以有下级节点
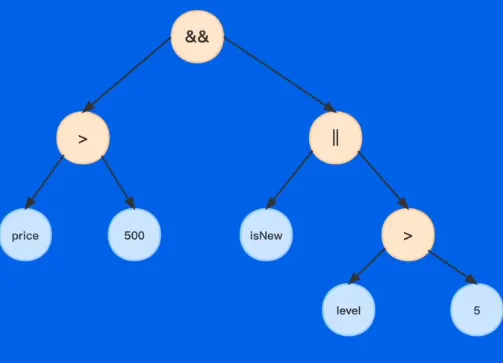
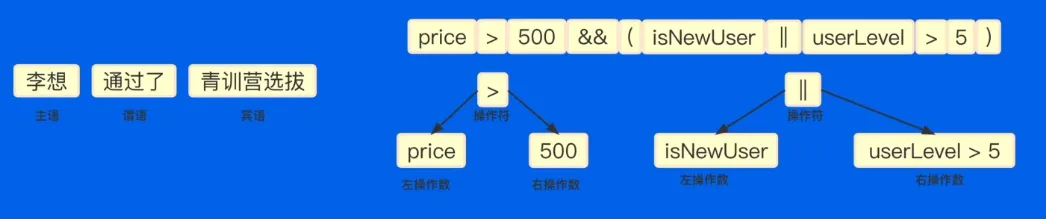
抽象语法树 Abstract Syntax Tree
- 上下文无关语法 Context-Free Grammar

- 语法句子无需考虑上下文,就可以判断正确性。可以使用巴科斯范式(BNF)来表达


- 产生式:一个表达式可以由另外已知类型的表达式或者符号推导产生
- 内置符号:字面量(string、bool、number)标识符、运算符
- 一个基础表达式可以由 常量(string、bool、number)或标识符(identifier)
- 一个乘法表达式可以由 基础表达式 或者 乘法表达式 * 基础表达式组成
- . . . . . .
- 递归下降算法 Recursive Descent Parsing
- 递归下降算法就是自顶向下构造语法树
- 不断的对 Token 进行语法展开(下降),展开过程中可能会遇到递归的情况
- 演示
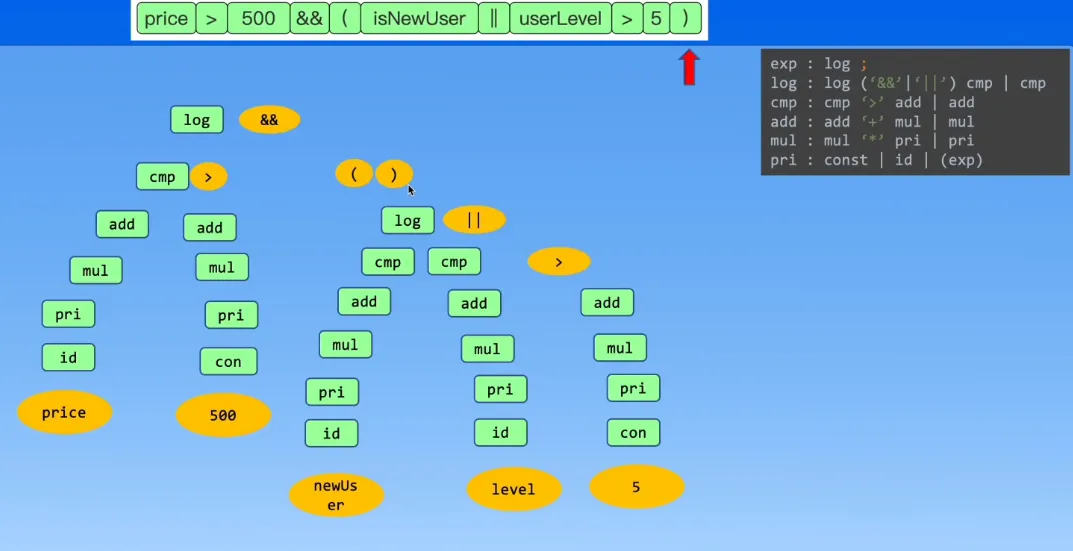
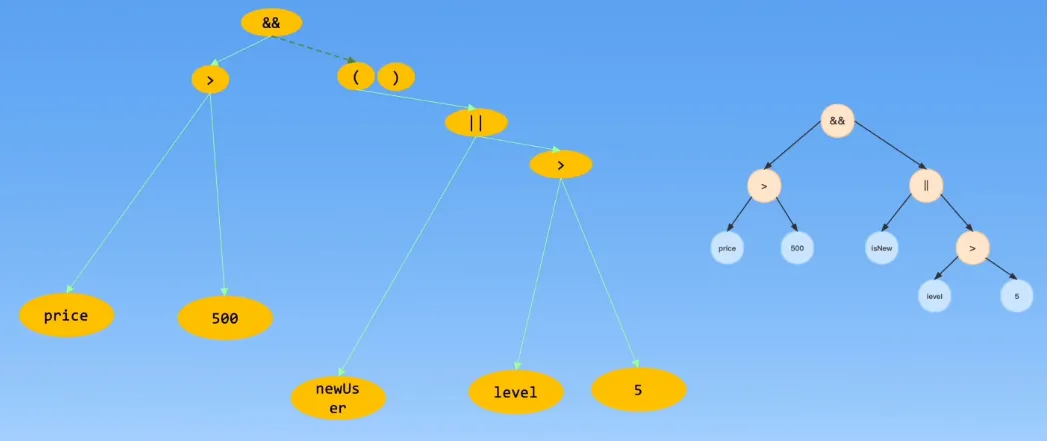
类型检查
- 类型综合
- 根据子表达式的类型构造出父表达式的类型。例如,表达式 A+B 的类型是根据 A 和 B 的类型定义的
- 根据子表达式的类型构造出父表达式的类型。例如,表达式 A+B 的类型是根据 A 和 B 的类型定义的
- 编译时检查 & 运行时检查
- 类型检查可以发生在表达式的编译阶段,即在构造语法树的阶段;也可以发生在执行时的阶段
- 编译时:需要提前声明参数的类型,在构建语法树的过程中进行类的检查
- 执行时:可以根据执行时的参数输入的值的类型,在执行过程中进行类型检查


设计一个规则引擎
设计目标
- 设计一个规则引擎,支持特定的语法、运算符、数据类型和优先级。并且基于以上预定义语法的规则表达式的编译和执行
- 词法(合法 Token)
- 参数:由字母数字下划线组成 eg:_ab2、user_name
- 布尔值:true、false
- 字符串:”abcd”、’abcd’、`abcd`
- 十进制 int:1234
- 十进制 float:123.5
- 预定义运算符:+ -
- 运算符
- 一元运算符:+ -
- 二元运算符:+ - * / % > < >= <= == !=
- 逻辑操作符:&& || !
- 括号:( )
- 数据类型
- 字符串
- 布尔值
- 十进制 int
- 十进制 float
- 优先级

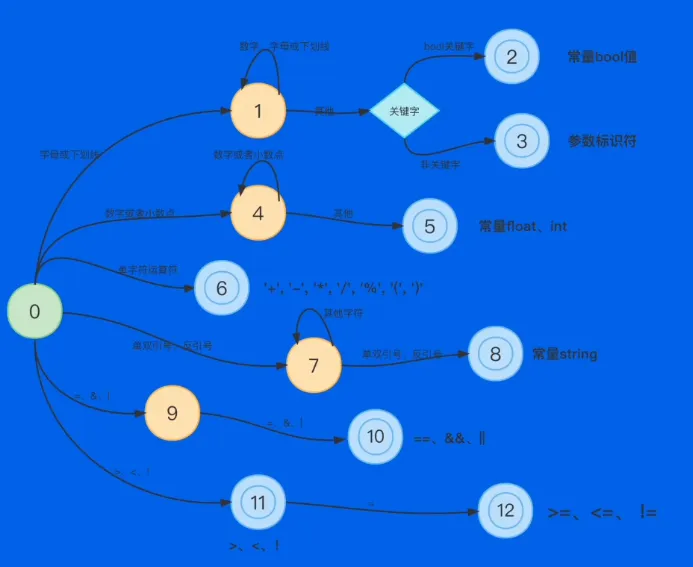
词法分析
- 参数:由字母数字下划线组成 eg:_ab2、user_name
- 布尔值:true、false
- 字符串:”abcd”、’abcd’、`abcd`
- 十进制 int:1234
- 十进制 float:123.5
- 预定义运算符:+ -
- 设计词法分析的状态机
语法分析

- 优先级的表达
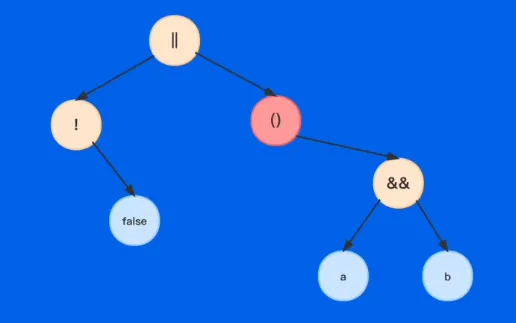
- 语法树结构
- 一元运算符:左子树为空,右子树为右操作数
- 二元运算符:左子树为左操作数,右子树为右操作数
- 括号:左子树为空,右子树为内部表达式的 AST

语法树执行与类型检查
- 语法树执行
- 预先定义好每种操作符的执行逻辑
- 对抽象语法树进行后续遍历执行,即:
- 先执行左子树,得到左节点的值
- 再执行右子树,得到右节点的值
- 最后根据根节点的操作符执行得到根节点的值
- 类型检查
- 检查时机:执行时检查
- 检查方法:在一个节点的左右子节点执行完成后,分别校验左右子节点的类型是否符合对应操作符的类型检查预设规则
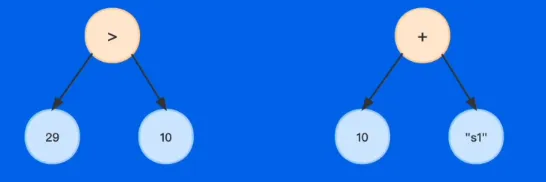
- ‘>’符号要求左右子节点的值都存在且为 int 或 float
- ‘!’符号要求左节点为空且右节点的值为 bool

