微服务架构介绍
系统架构演变历史
- 为什么系统架构需要演进?
- 互联网的爆炸性发展
- 硬件设施的快速发展
- 需求复杂性的多样化
- 开发人员的急剧增加
- 计算机理论及技术的发展
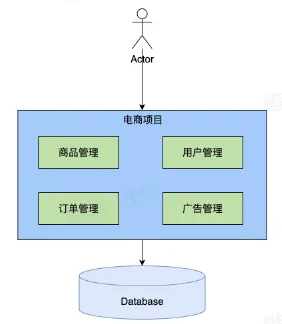
- 单体架构——all in one process
- 优势:
- 性能最高
- 冗余小
- 劣势:
- debug 困难
- 模块相互影响
- 模块分工、开发流程
- 优势:
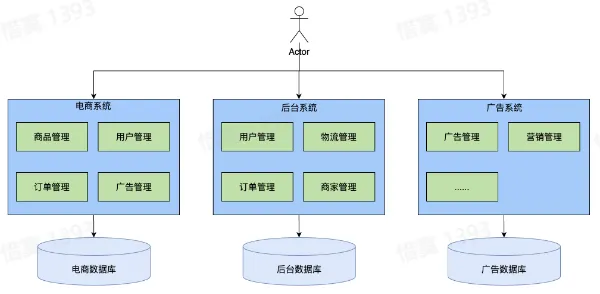
- 垂直应用架构——按照业务线垂直划分
- 优势:
- 业务独立开发维护
- 劣势:
- 不同业务存在冗余
- 每个业务还是单体
- 优势:
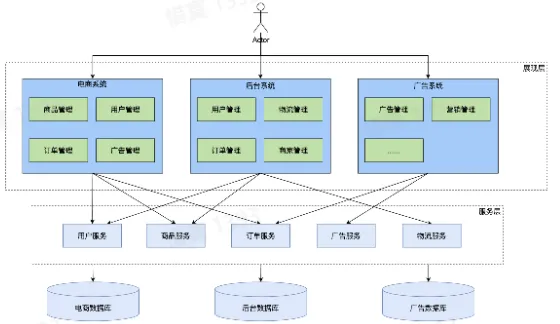
- 分布式架构——抽出与业务无关的公共模块
- 优势:
- 业务无关的独立服务
- 劣势:
- 服务模块 bug 可导致全站瘫痪
- 调用关系复杂
- 不同服务冗余
- 优势:
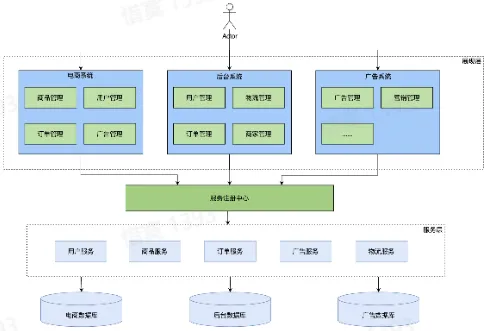
- SOA 架构——面向服务
- 优势:
- 服务注册
- 劣势:
- 整个系统设计是中心化的
- 需要从上至下设计
- 重构困难
- 优势:
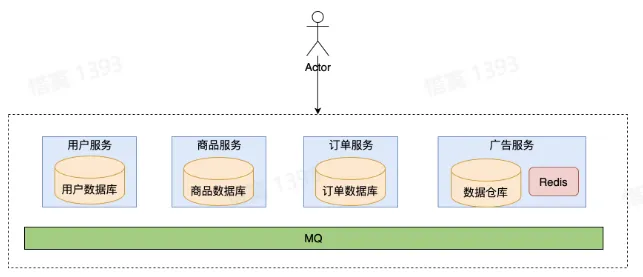
- 微服务架构——彻底的服务化
- 优势:
- 开发效率
- 业务独立设计
- 自上而下
- 故障隔离
- 劣势:
- 治理、运维难度
- 观测挑战
- 安全性
- 分布式系统
- 优势:
微服务架构概览
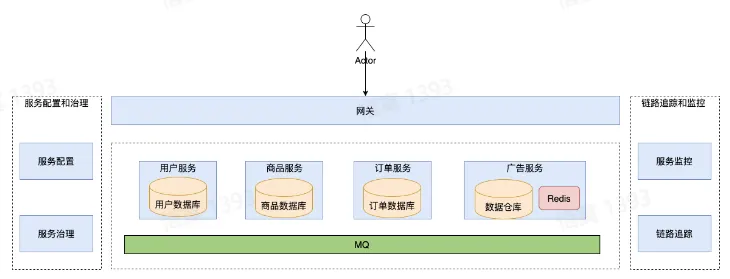
微服务架构核心要素
- 服务治理
- 服务注册
- 服务发现
- 负载均衡
- 扩缩容
- 流量治理
- 稳定性治理
- 可观测性
- 日志采集
- 日志分析
- 监控打点
- 监控大盘
- 异常报警
- 链路追踪
- 安全
- 身份验证
- 认证授权
- 访问令牌
- 审计
- 传输加密
- 黑产攻击
微服务架构原理及特征
基本概念
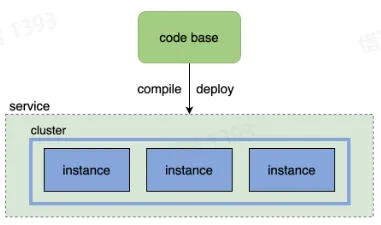
服务(service)
- 一组具有相同逻辑的运行实体
实例(instance)
- 一个服务中,每个运行实体即为一个实例
实例与进程的关系
- 实例与进程之间没有必然对应关系,一个实例可以对应一个或多个进程(反之不常见)
集群(cluster)
- 通常指服务内部的逻辑划分,包含多个实例
常见的实例承载形式
- 进程、VM、k8s pod……
有状态/无状态服务
- 服务的实例是否存储了可持久化的数据(例如磁盘文件)
服务间通信
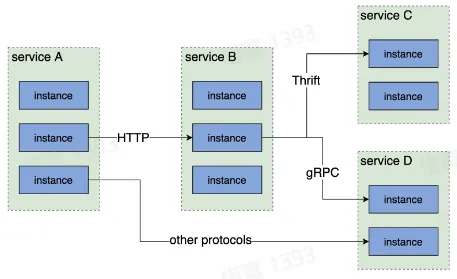
- 对于单体服务,不同模块通信只是简单的函数调用
- 对于微服务,服务间通信意味着网络传输
服务注册与发现
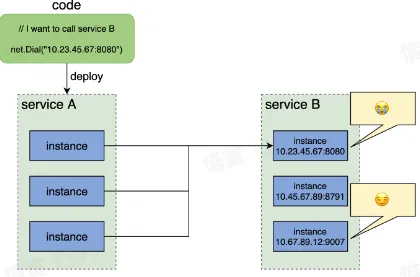
- 问题:在代码层面,如何指定调用一个目标服务的地址(ip:port)?
- 直接指定 ip:port?
- 没有任何动态能力
- 有多个实例下游实例怎么办?
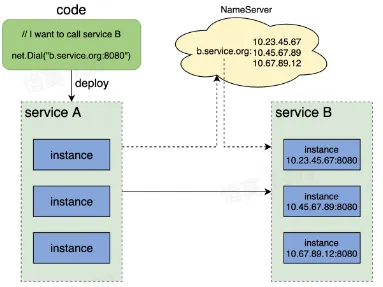
- 使用 DNS?
- 本地 DNS 存在缓存,导致延迟
- 负载均衡问题
- 不支持服务探活检查
- 域名无法配置端口
- 直接指定 ip:port?
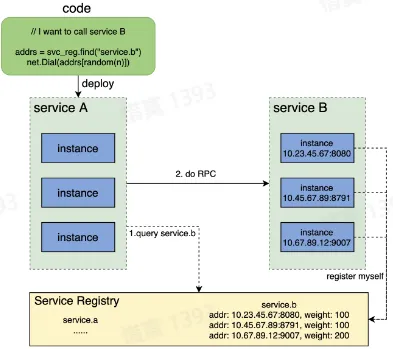
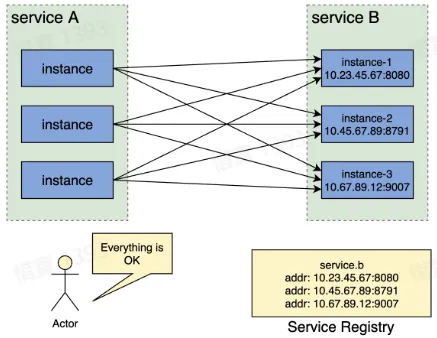
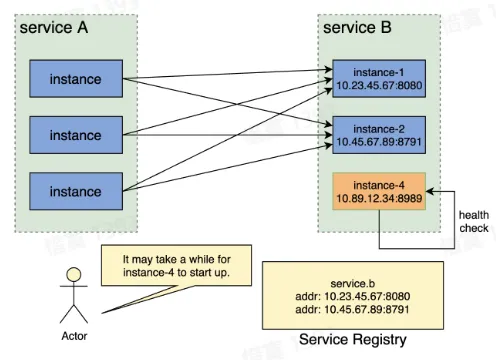
- 解决思路:新增一个统一的服务注册中心,用于存储服务名到服务实例之间的映射关系
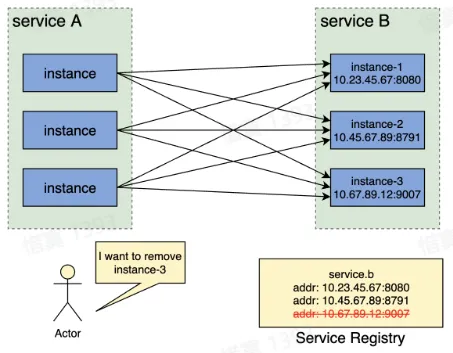
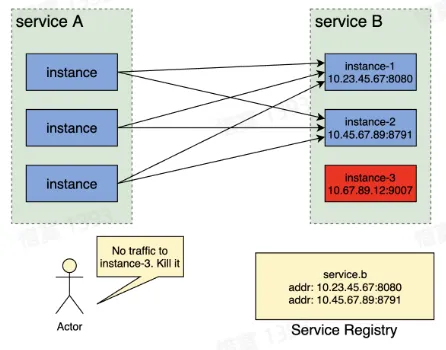
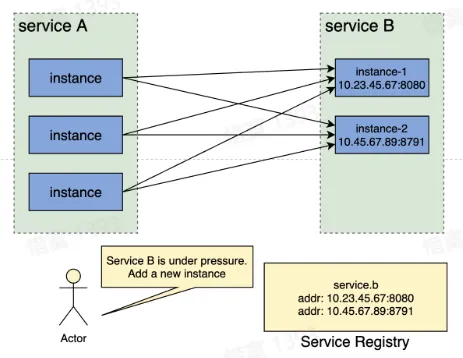
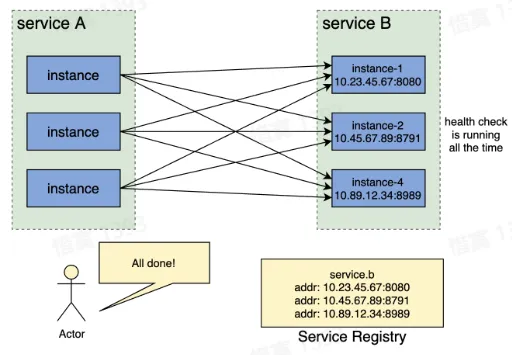
- 服务实例上线及下线过程
- 旧服务实例下线前,从服务注册中心删除该实例,下线流量
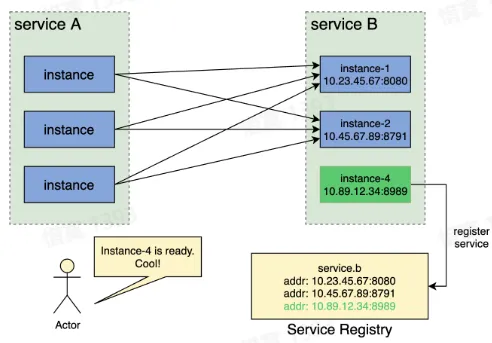
- 新服务实例上线后,在服务注册中心注册该实例,上线流量
- 旧服务实例下线前,从服务注册中心删除该实例,下线流量
流量特征
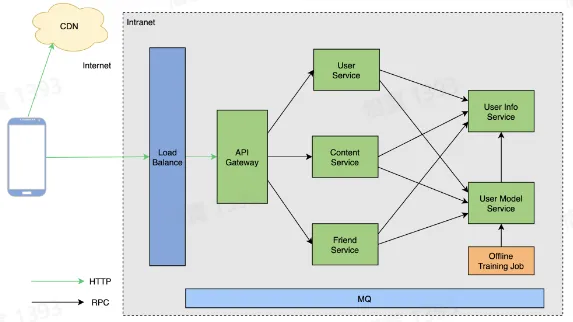
- 统一网关入口
- 内网通信多数采用 RPC(Thrift, gRPC)
- 网状调用链路
核心服务治理功能
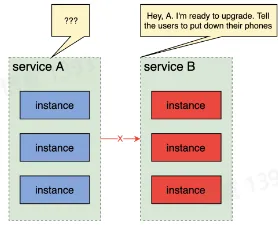
服务发布
- 服务发布(deployment)
- 让一个服务升级运行新的代码的过程
- 服务发布的难点
- 服务不可用
- 服务抖动
- 服务回滚
- 服务不可用
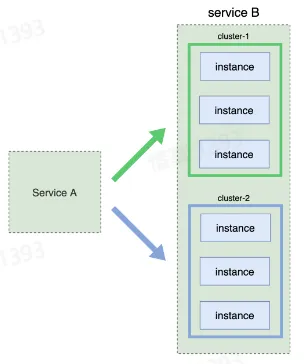
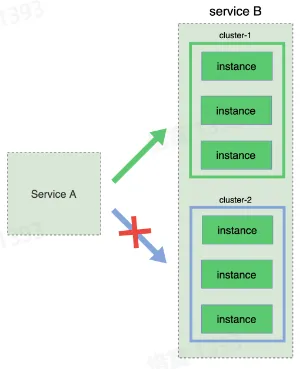
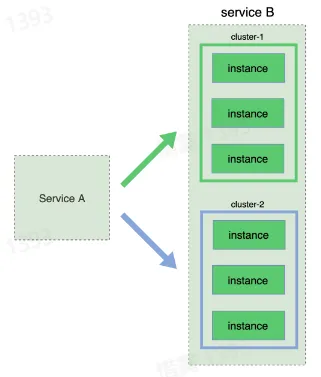
- 蓝绿部署
- 将服务分成两个部分,分别先后发布
- 简单、稳定
- 但需要两倍资源
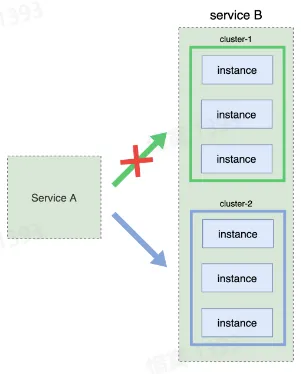
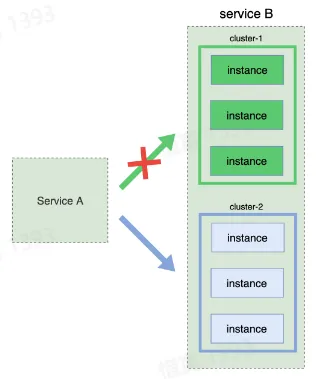
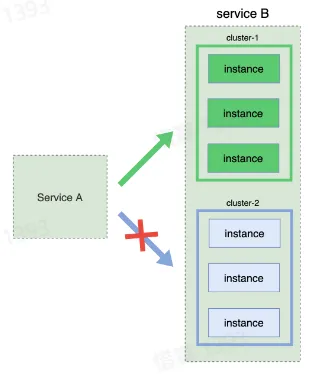
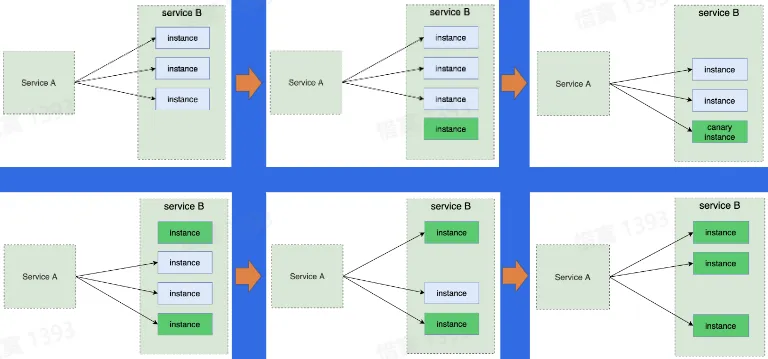
- 灰度发布(金丝雀发布)
- 先发布少部分实例,接着逐步增加发布比例
- 不需要增加资源
- 回滚难度大,基础设施要求高
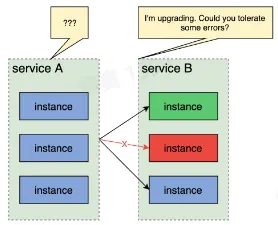
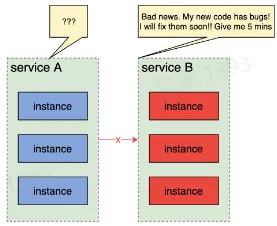
流量治理
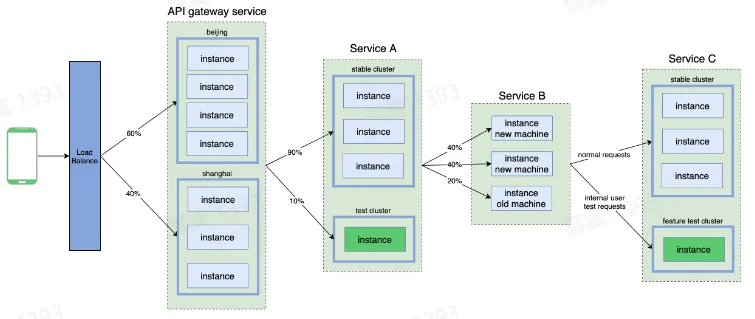
在微服务架构中,可以基于地区、集群、实例、请求等维度,对端到端流量的路由路径进行精确控制
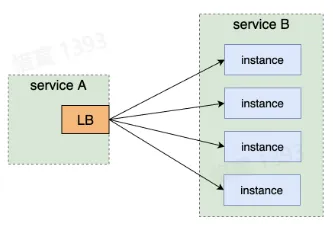
负载均衡
- 负载均衡(Load Balance)负责分配请求在每个下游实例上的分布
- 常见的 LB 策略
- Round Robin
- Random
- Ring Hash
- Least Request
稳定性治理
- 线上服务总是会出问题的,这与程序的正确性无关
- 网络攻击
- 流量突增
- 机房断电
- 光纤被挖
- 机器故障
- 网络故障
- ……
- 微服务架构中典型的稳定性治理功能
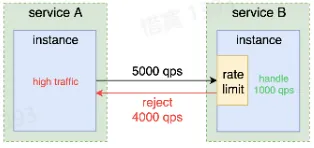
- 限流
- 限制服务处理的最大 QPS,拒绝过多请求
- 熔断
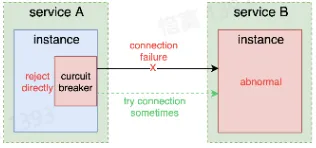
- 中断请求路径,增加冷却时间从而让故障实例尝试恢复
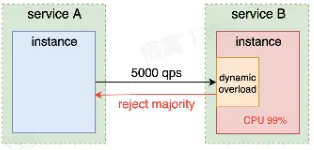
- 过载保护
- 在负载高的实例中,主动拒绝一部分请求,防止实例被打挂
- 降级
- 服务处理能力不足时,拒绝低级别的请求,只响应线上高优请求
- 限流
字节跳动服务治理实践
重试的意义
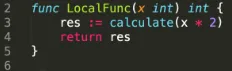
- 本地函数调用——通常没有重试意义
- 可能有哪些异常?
- 参数非法
- OOM(Out Of Memory)
- NPE(Null Pointer Expection)
- 边界 case
- 系统崩溃
- 死循环
- 程序异常退出
- 远程函数调用
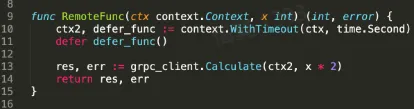
- 可能有哪些异常?
- 网络抖动
- 下游负载高导致超时
- 下游机器宕机
- 本地机器负载高,调度超时
- 下游熔断、限流
- ……
- 重试的意义
- 重试可以避免掉偶发的错误,提高 SLA(Service-Level Agreement)
- 降低错误率
- 假设单次请求的错误概率为 0.01,那么连续两次错误概率则为 0.0001
- 降低长尾延时
- 对于偶尔耗时较长的请求,重试请求有机会提前返回
- 容忍暂时性错误
- 某些时候系统会有暂时性异常(例如网络抖动),重试可以尽量规避
- 避开下游故障实例
- 一个服务中可能会有少量实例故障(例如机器故障),重试其他实例可以成功
- 重试可以避免掉偶发的错误,提高 SLA(Service-Level Agreement)
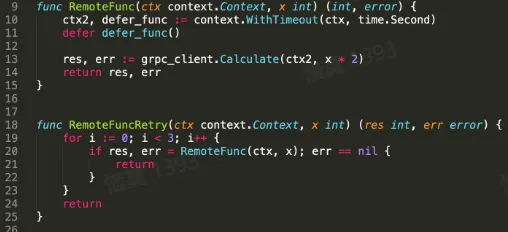
重试的难点
- 幂等性
- 多次请求可能会造成数据不一致
- 重试风暴
- 随着调用链路的增加,重试次数呈指数级上升
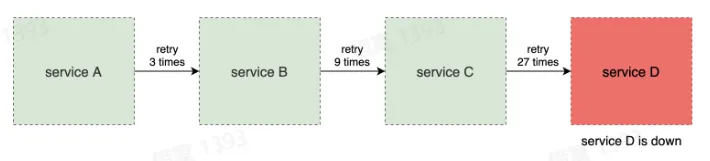
- 超时设置
- 假设调用时间一共 1s,经过多少时间开始重试?
重试策略
- 限制重试比例
- 设定一个重试比例阈值(例如 1%),重试次数占所有请求比例不超过该阈值
- 重试只有在大部分请求都成功,只有少量请求失败时才有必要
- 如果大部分请求都失败,重试只会加剧问题严重性
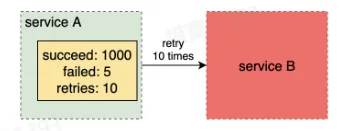
- 防止链路重试
- 链路层面的防重试风暴的核心是限制每层都发生重试,理想情况下只有最下一层发生重试
- 可以返回特殊的 status code,表示“请求失败,但别重试”

- Hedged Requests
- 对于可能超时(或延时高)的请求,重新向另一个下游实例发送一个相同的请求,并等待先到达的响应
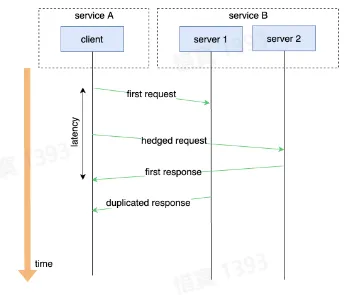
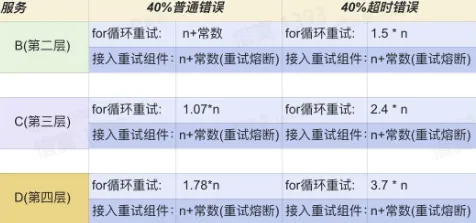
重试效果验证
实际验证经过上述重试策略后,在链路上发生的重试放大效应