引入
案例一:系统崩溃
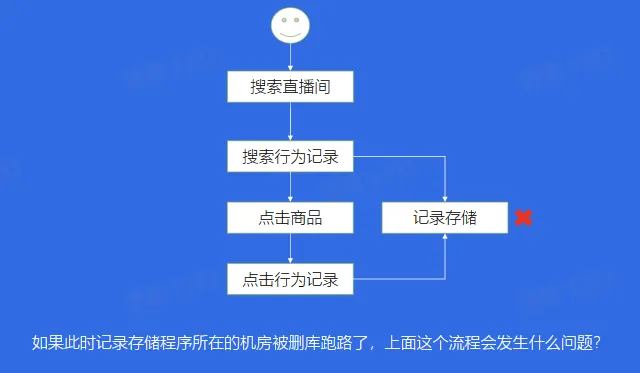
- 解决方案:解耦
案例二:服务能力有限
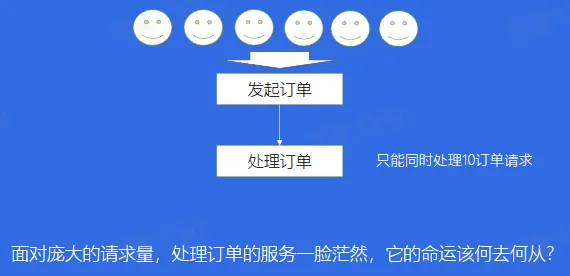
- 解决方案:削峰
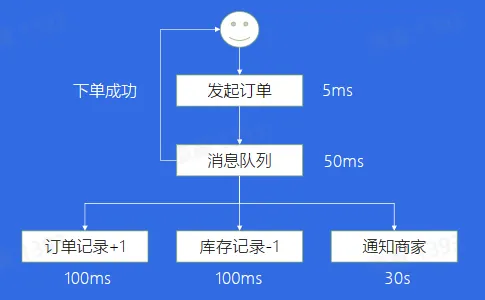
案例三:链路耗时长尾
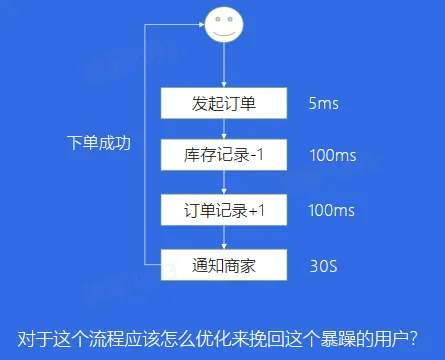
- 解决方案:异步
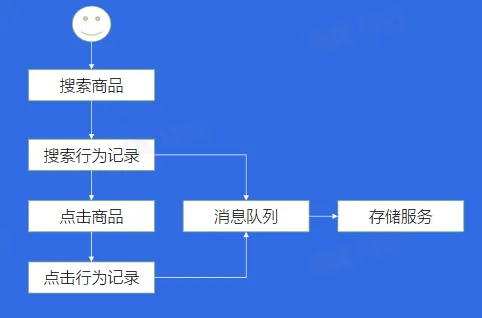
案例四:日志存储
- 服务器故障日志丢失
- 解决方案:
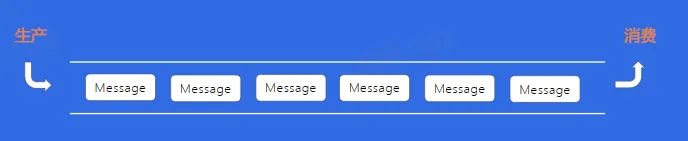
什么是消息队列?
- 消息队列(MQ),指保存消息的一个容器,本质是个队列,但这个队列需要支持高吞吐、高并发、并且高可用


前世今生
消息队列发展历程

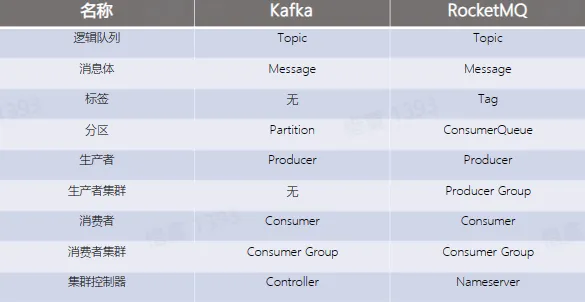
业内消息队列对比

消息队列-Kafka
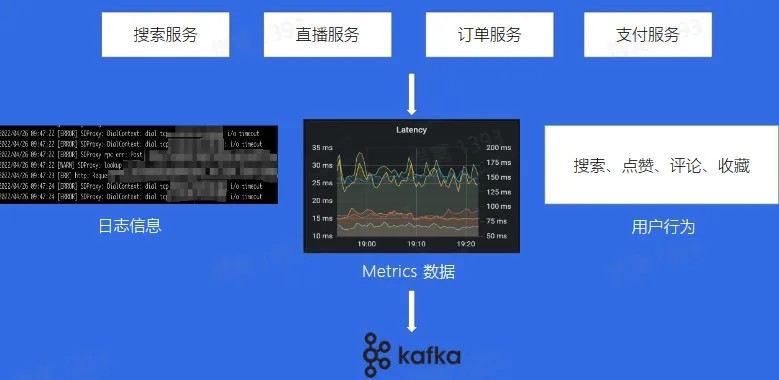
使用场景
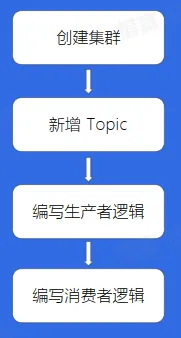
如何使用 Kafka
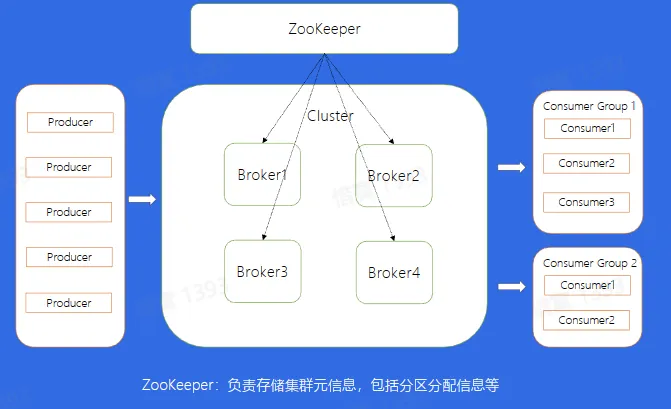
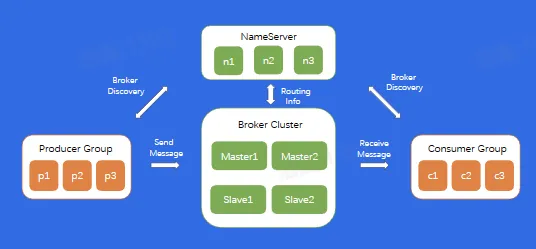
基本概念
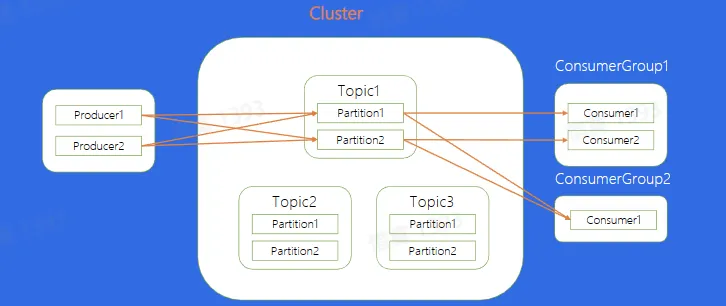
Topic:逻辑队列,不同 Topic 可以建立不同的 Topic
Cluster:物理集群,每个集群中可以建立多个不同的 Topic
Producer:生产者,负责将业务消息发送到 Topic 中
Consumer:消费者,负责消费 Topic 中的消息
ConsumerGroup:消费者组,不同组 Consumer 消费进度互不干涉
Offset:消息在 partition 内的相对位置信息,可以理解为唯一 ID,在 partition 内部严格递增
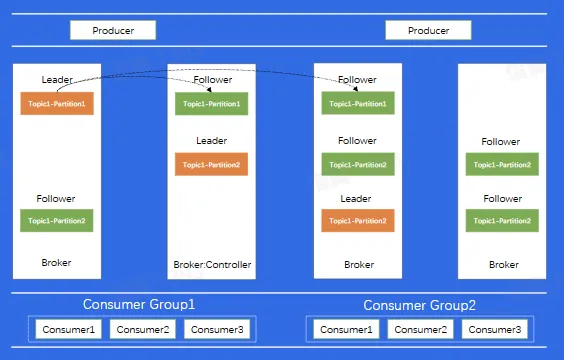
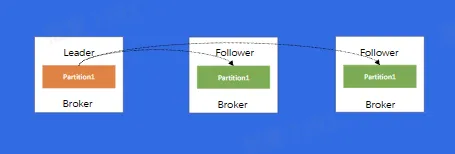
Replica:每个分片有多个 Replica,Leader Replica 将会从 ISR 中选出

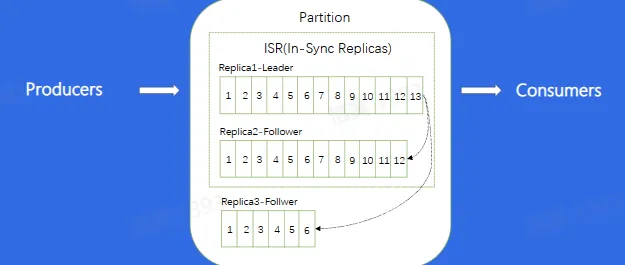
数据复制
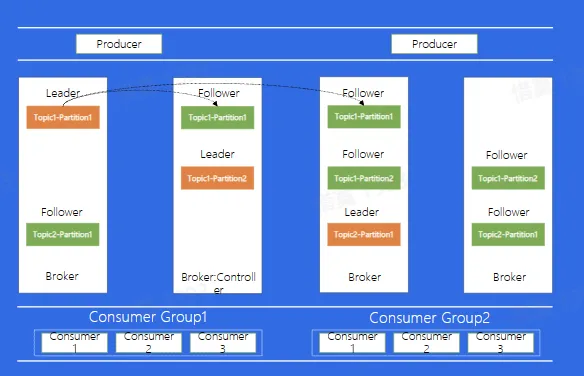
Kafka 架构
一条消息的自述

- 从一条消息的视角,看看为什么 Kafka 能支撑这么高的吞吐?
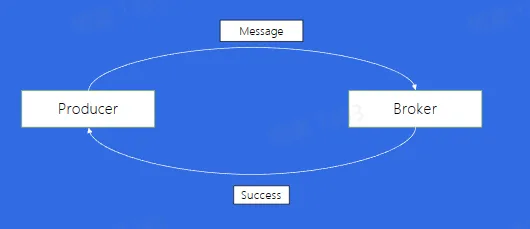
- 如果发送一条消息,等到其成功后再发一条会有什么问题?
Producer
- 批量发送
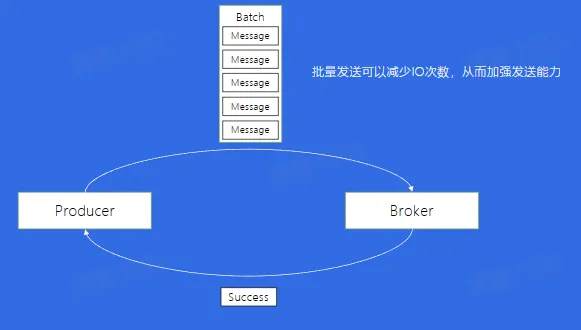
- 如果消息量很大,网络宽带不够用,如何解决?
- 数据压缩
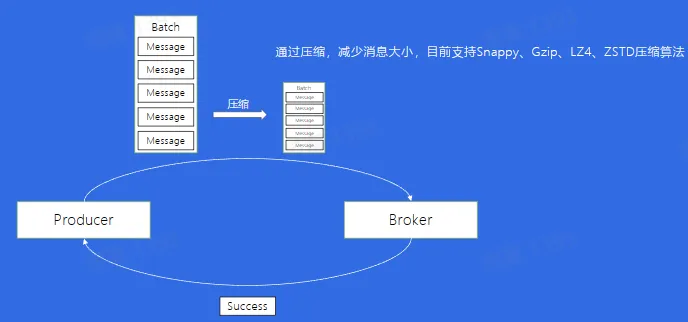
Broker
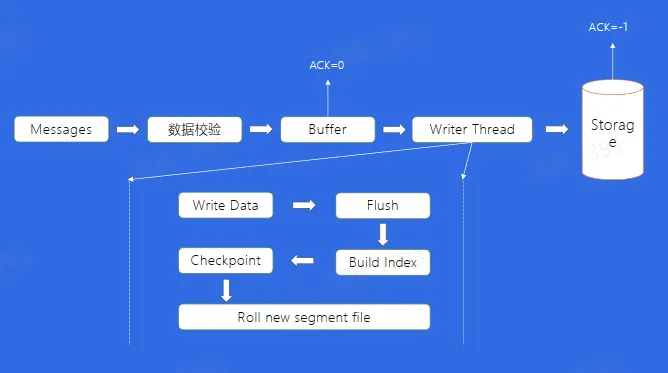
- 数据的存储
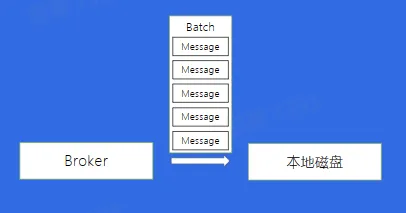
- 如何存储到磁盘?
- 消息文件结构
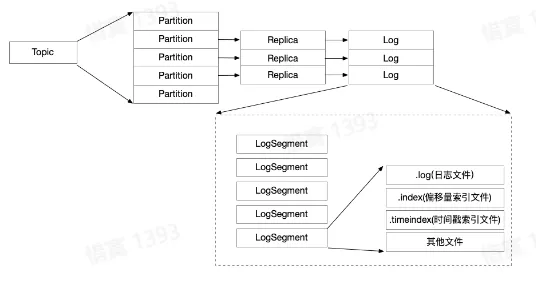
- 数据路径:/Topic/Partition/Segment/(log | index |timeindex | …)
- 磁盘结构
- 移动磁头找到对应磁道,磁盘转动。找到对应扇区,最后写入,寻道成本比较高,因此顺序可以减少寻道所带来的时间成本
- 顺序写

- 采用顺序写的方式进行写入,以提高写入效率
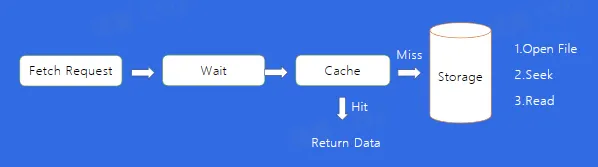
- 如何找到消息
- Consumer 通过发送 FetchRequest 请求消息数据,Broker 会将指定 Offset 处的消息,按照时间窗口和消息大小窗口发送给 Consumer,寻找数据这个细节是如何做到的呢?
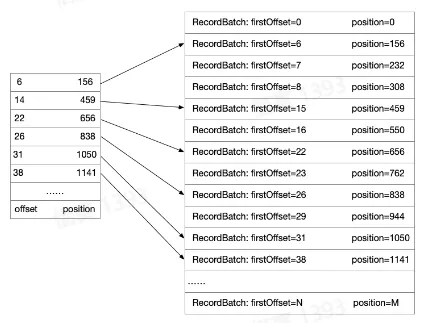
- 偏移量索引数据
- 目标:寻找 offset = 28

- 二分找到小于目标 offset 的最大文件
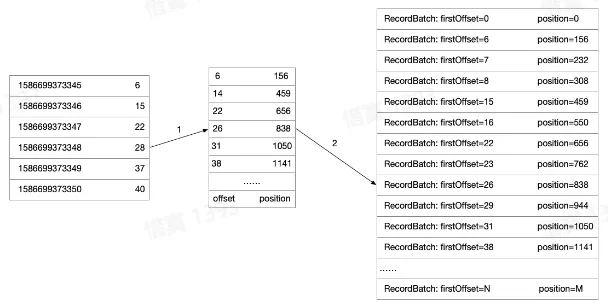
- 时间戳索引文件
- 二分找到小于目标时间戳最大的索引位置,在通过寻找 offset 的方式找到最终数据
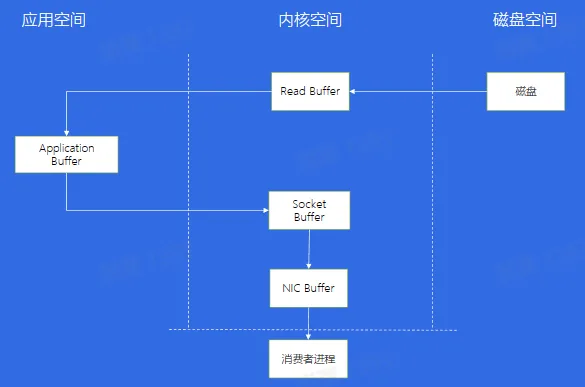
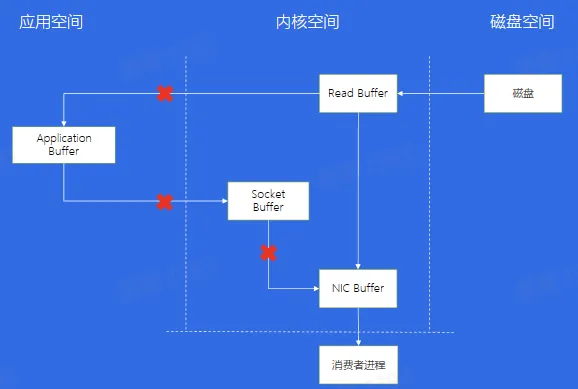
- 传统数据拷贝
- 零拷贝
Consumer
- 消息的接收端
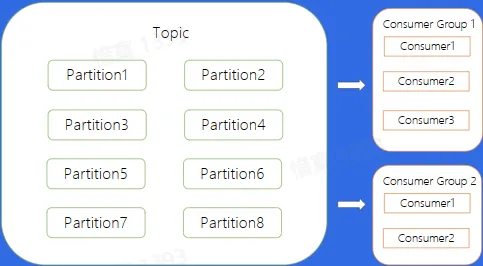
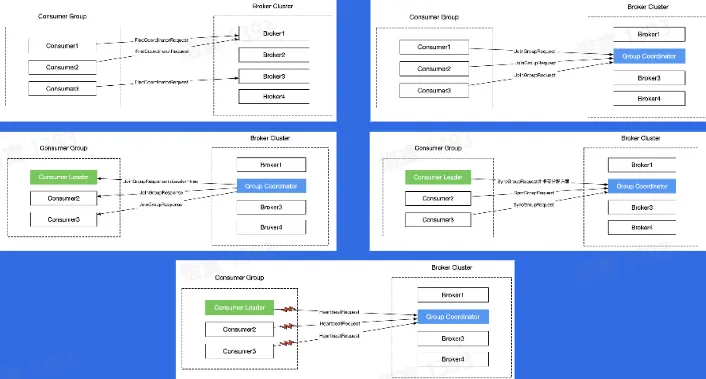
- 如何解决 Partition 在 Consumer Group 中的分配问题?
- Low Level
- 通过手动进行分配,哪一个 Consumer 消费哪一个 Partition 完全由业务来决定

- 这种方式的缺点是什么?
- 如果 Consumer3 挂掉了,7,8 分片就停止消费了
- 如果新增了一台 Consumer4 ,需要重新停掉整个集群,重新修改配置再上线,保证 Consumer4 也可以消费数据
- High Level
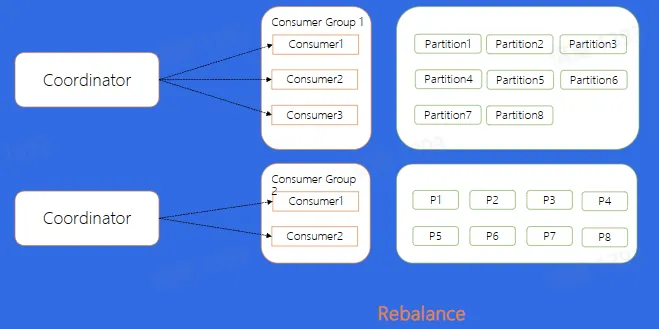
- Rebalance
一些可以帮 Kafka 提高吞吐或者稳定性的功能
- Producer:批量发送、数据压缩
- Broker:顺序写,消息索引,零拷贝
- Consumer:Reblance
问题
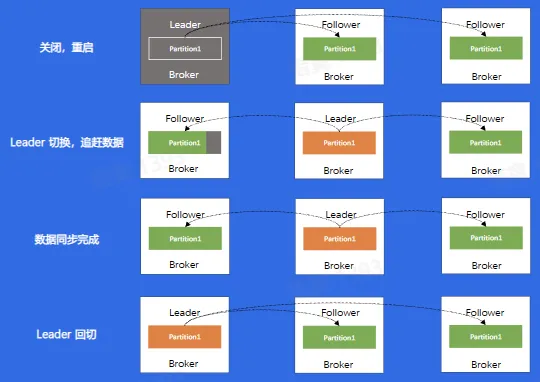
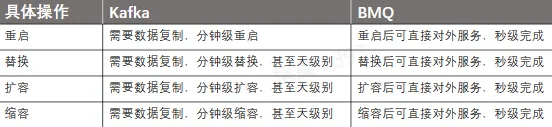
- 数据复制问题
- 重启操作
- 替换、扩容、缩容
- 负载不均衡
- 问题总结
- 运维成本高
- 对于负载不均衡的场景,解决方案复杂
- 没有自己的缓存,完全依赖 Page cache
- Controller 和 Coordinator 和 Broker 在同一进程中,大量 IO 会造成其性能下降
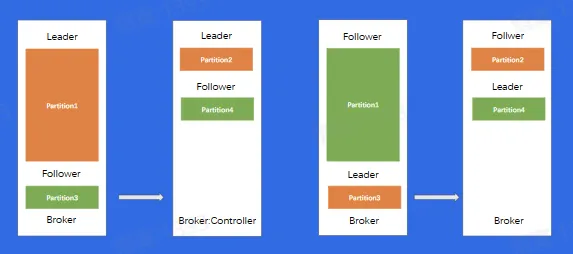
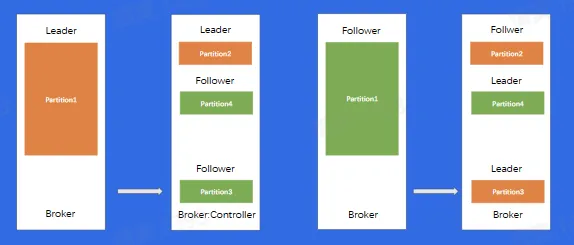
消息队列-BMQ
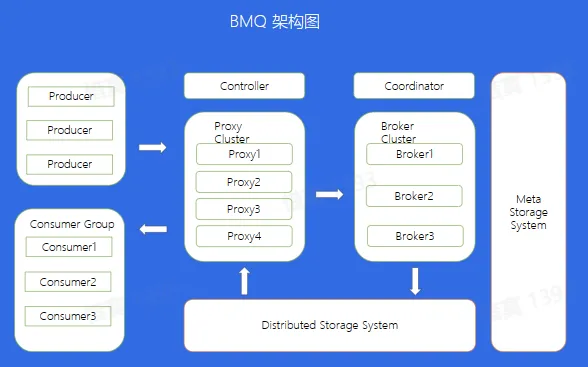
BMQ 简介
兼容 Kafka 协议,存算分离,云原生消息队列
BMQ 介绍
运维操作对比
HDFS 写文件流程

BMQ 文件结构
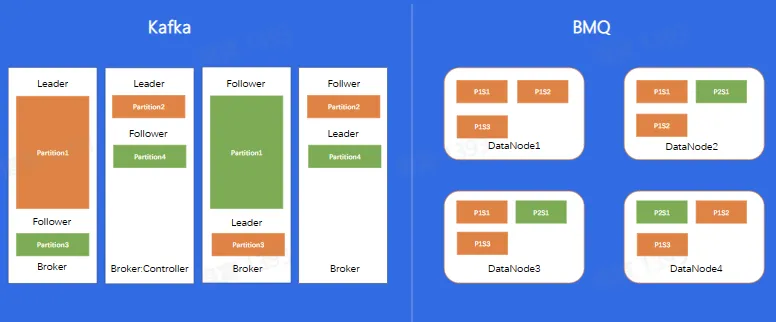
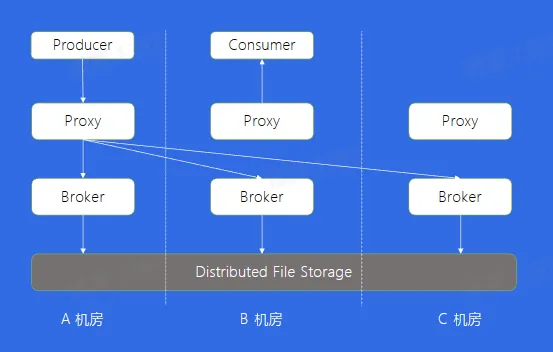
Broker
- Partition 状态机
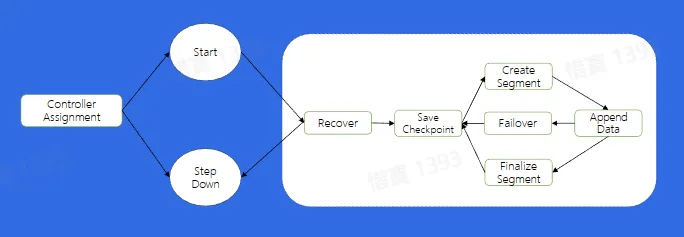
- 保证对于任意分片在同一时刻只能在一个 Broker 上存活
- 写文件流程
- 写文件 Failover

- 如果 DataNode 节点挂了或者是其他原因导致我们写文件失败,应该如何处理?
Proxy
多机房部署
高级特性
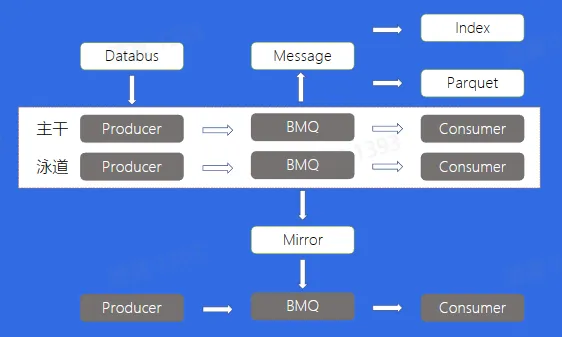
泳道消息
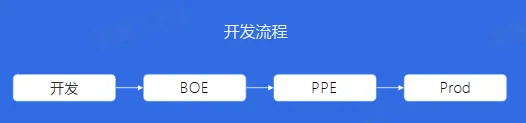
- BOE:Bytedance Offline Environment,是一套完全独立的线下机房环境
- PPE:Product Preview Environment,即产品预览环境
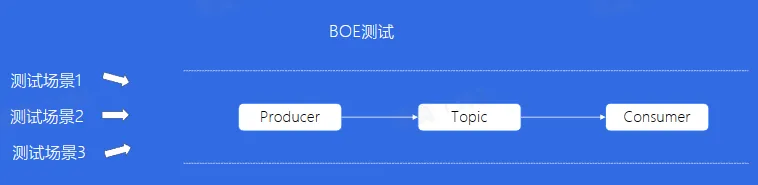
多个人同时测试,需要等待上一个人测试完成
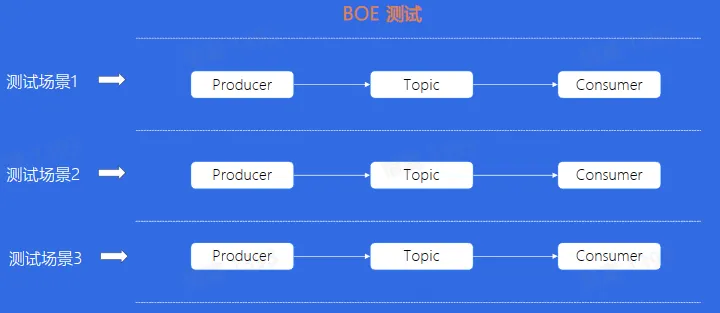
每多一个测试人员,都需要重新搭建一个相同配置的 Topic,造成人力和资源的浪费
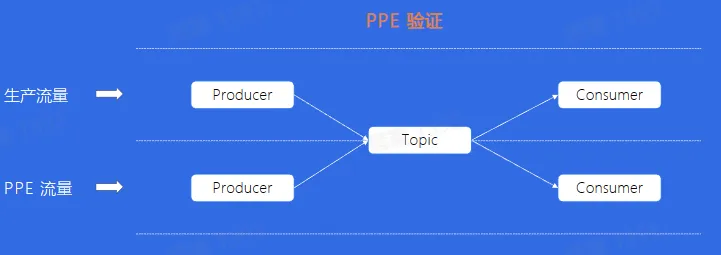
对于 PPE 的消费者来说,资源没有生产环境多,所以无法承受生产环境的流量
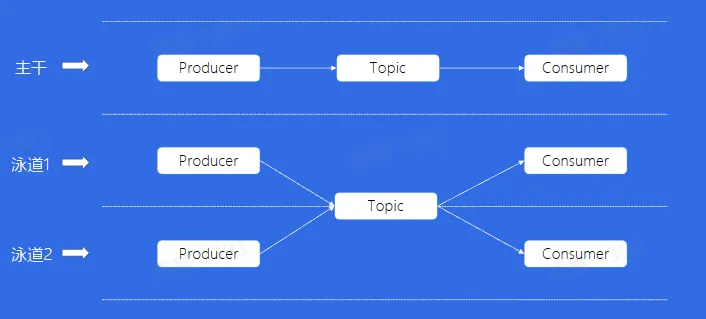
解决主干泳道流量隔间问题以及泳道资源重复创建问题
Databus
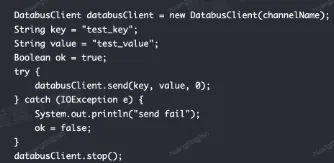
- 直接使用原生 SDK 会有什么问题?
- 客户端配置较为复杂
- 不支持动态配置
- 对于 latency 不是很敏感的业务,batch 效率不佳
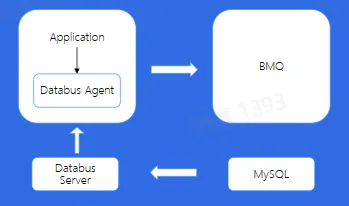
- 简化消息队列客户端复杂配置
- 解耦业务与 Topic
- 缓解集群压力,提高吞吐
Mirror
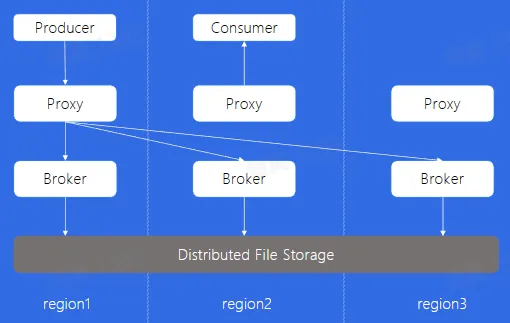
是否可以通过多机房部署的方式,解决跨 Region 读写的问题?
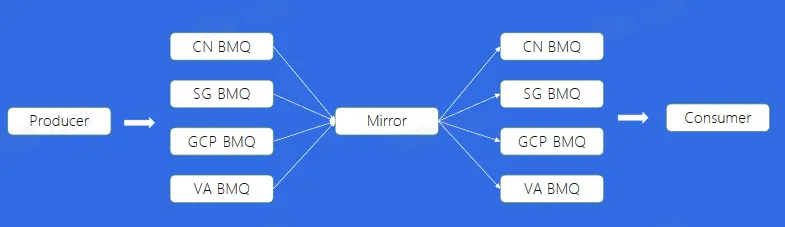
使用 Mirror 通过最终一致的方式,解决跨 Region 读写问题
Index

如果希望通过写入的 LogId、UserId 或者其他的业务字段进行消费的查询,应该怎么做?
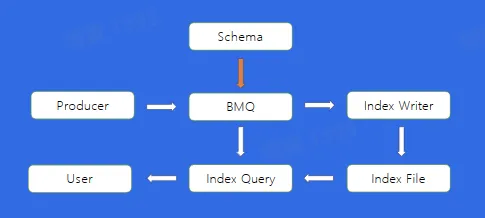
直接在 BMQ 中将数据结构化,配置索引 DDL,异步构建索引后,通过 Index Query 服务读出数据
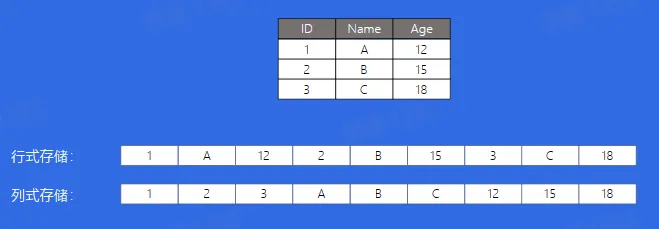
Parquet
Apache Parquet 是 Hadoop 生态圈中一钟新型列式存储格式,它可以兼容 Hadoop 生态圈中大多数计算框架(Hadoop、Spark 等),被多种查询引擎支持(Hive、Impala、Drill 等)
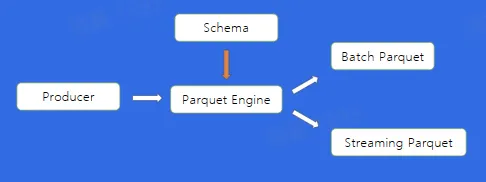
直接在 BMQ 中将数据结构化,通过 Parquet Engine,可以使用不同的方式构建 Parquet 格式文件
小结
- BMQ 的架构模型(解决 Kafka 存在的问题)
- BMQ 读写流程(Failover 机制,写入状态机)
- BMQ 高级特性(泳道、Databus、Mirror、Index、Parquet)
消息队列-RocketMQ
使用场景
例如,针对电商业务线,其业务涉及广泛,如注册、订单、库存、物流等;同时,也会涉及许多业务峰值时刻,如秒杀活动、周年庆、定期特惠等
基本概念
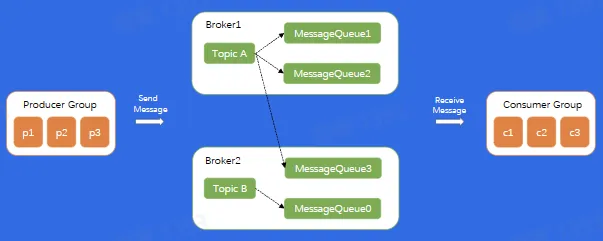
架构
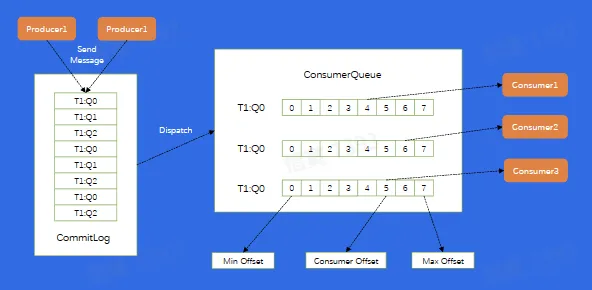
存储模型
高级特性
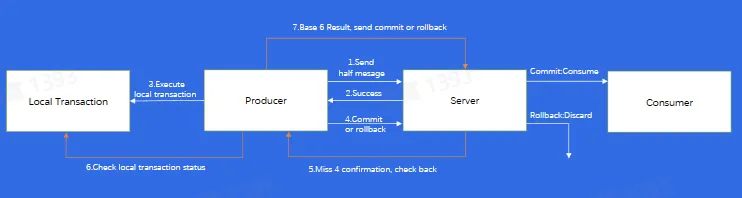
事务场景
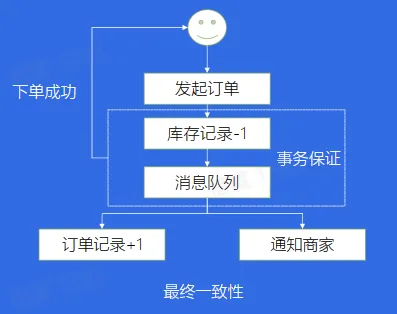
事务消息
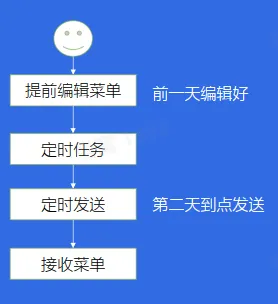
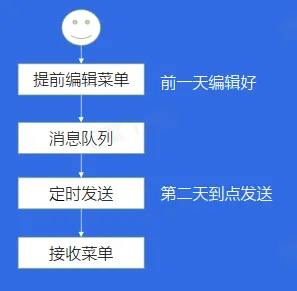
延迟发送
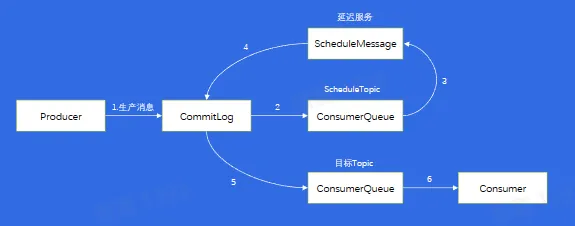
延时消息
处理失败
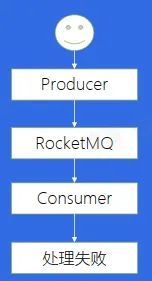
该如何处理失败的消息呢?
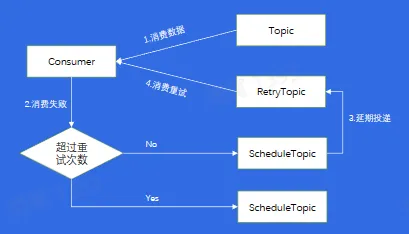
消费重试和死信队列
小结
- RocketMQ 的基本概念(Queue、Tag)
- RocketMQ 的底层原理(架构模型、存储模型)
- RocketMQ 的高级特性(事务消息、重试和死信队列、延迟队列)

