Redis 是什么
- 为什么需要 Redis
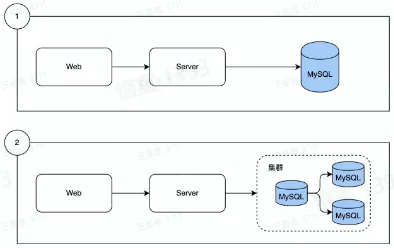
- 数据从单表,演进出了分库分表
- Mysql 从单机演进出了集群
- 数据量增长
- 读写数据压力的不断增加
- 数据分冷热
- 热数据:经常被访问到的数据
- 将热数据存储到内存中
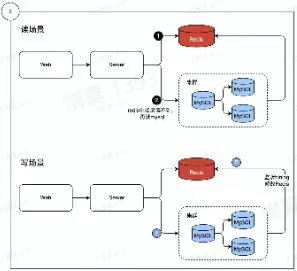
- 数据从单表,演进出了分库分表
- Redis 基本工作原理
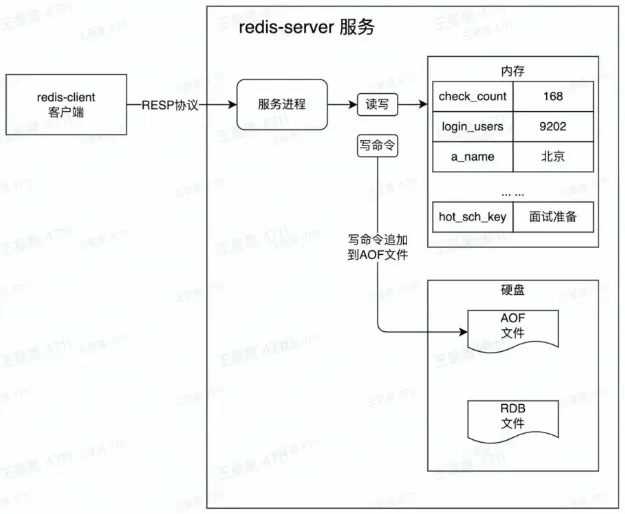
- 数据从内存中读写
- 数据保存到硬盘上防止重启数据丢失
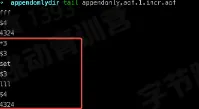
- 增量数据保存到 AOF 文件
- 全量数据 RDB 文件
- 增量数据保存到 AOF 文件
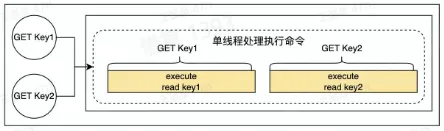
- 单线程处理所有操作命令

Redis 应用案例
- 1、连续签到
- 掘金每日连续签到
- 用户每日有一次签到机会,如果断签,连续签到计数将归为 0
- 连续签到的定义:每天必须在 23:59:59 前签到

- Key:cc_uid_1165894833417101
- value:252
- expireAt:后天的零点
- String 数据结构
- 数据结构-sds
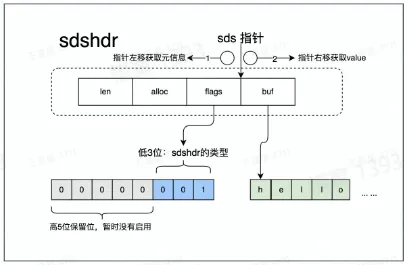
- 可以存储字符串、数字、二进制数据
- 通常和 expire 配合使用
- 场景:存储计数、Session
- 掘金每日连续签到
- 2、消息通知
- 用 list 作为消息队列
- 使用场景:消息通知
- 例如当文章更新时,将更新后的文章推送到 ES,用户就能搜索到最新的文章数据
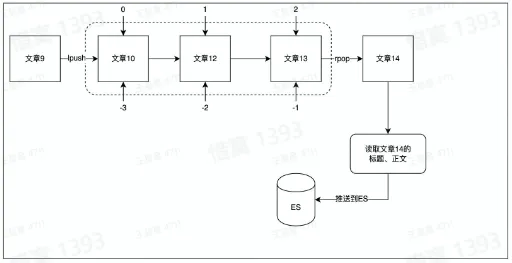
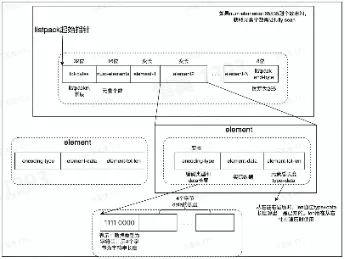
- List 数据结构 Quicklist
- Quicklist 由一个双向链表和 listpack 实现
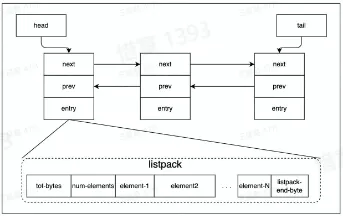
- Listpack 数据结构
- 3、计数
- 一个用户有多项计数需求,可通过 hash 结构存储
- Hash 数据结构 dict
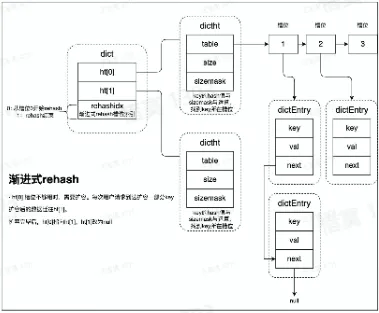
- rehash:rehash 操作是将 ht[O]中的数据全部迁移到 ht[1]中。数据量小的场景下直接将数据从 ht[O 拷贝到 ht[1]速度是较快的。数据量大的场景,例如存有上百万的 KV 时,迁移过程将会明显阻塞用户请求
- 渐进式 rehash:为避免出现这种情况,使用了 rehash 方案。基本原理就是,每次用户访问时都会迁移少量数据。将整个迁移过程,平摊到所有的访问用不请求过程中
- 排行榜
- 积分变化时,排名要实时变更
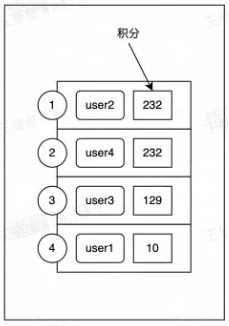
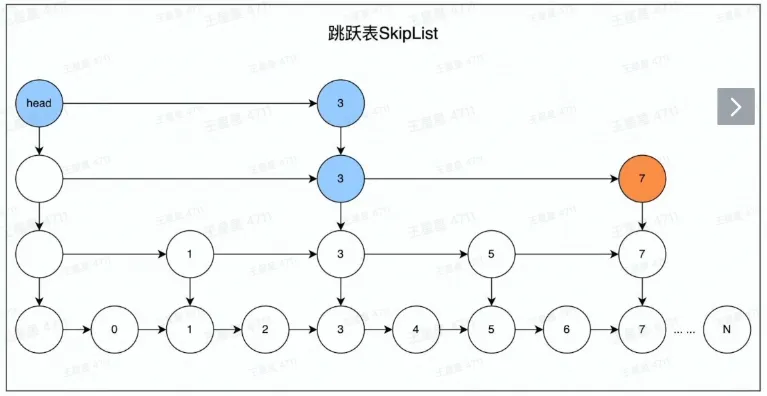
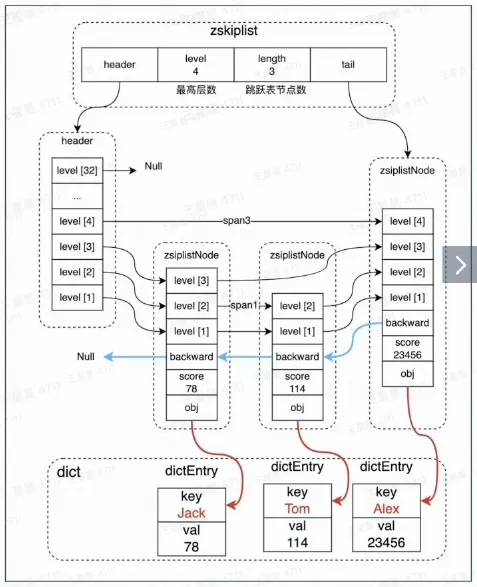
- zset 数据结构 zskiplist
- 查找数字 7 的路径,head,3,3,7
- 结合 dict 时,可实现通过 key 操作跳表的功能
- ZINCRBY myzset 2 “Alex”
- ZSCORE myzset “Alex”
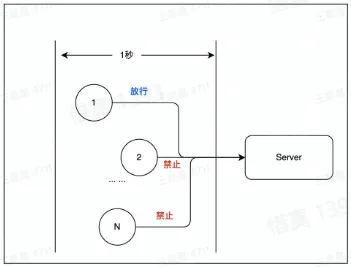
- 5、限流
- 要求 1 秒内放行的请求为 N,超过 N 则禁止访问
- Key:comment_freq_limit_1671356046
- 对这个 Key 调用 incr,超过限制 N 则禁止访问
- 1671356046 是当前时间戳
- 分布式锁
- 并发场景,要求一次只能有一个协程运行,执行完成后,其他等待中的协程才能执行
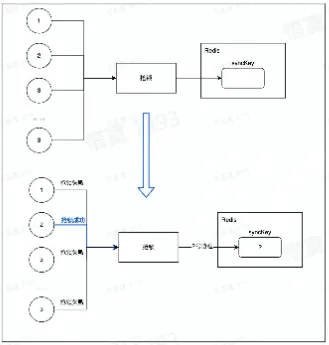
- 可以使用 redis 的 setnx 实现,利用了两个特性
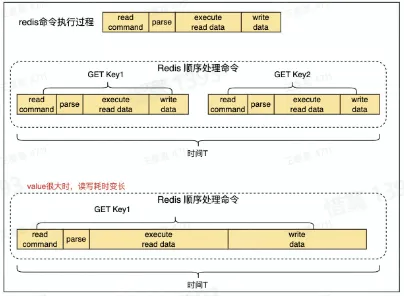
- Redis 是单线程执行命令
- setnx 只有未设置过才能执行成功
Redis 使用注意事项
大 Key、热 Key
大 Key 的定义
大 Key 的危害
- 读取成本高
- 容易导致慢查询(过期、删除)
- 主从复制异常,服务组塞无法正常响应请求
业务侧使用大 Key
- 请求 Redis 超时报错
消除大 Key 的方法
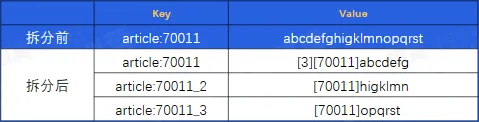
- 1、拆分
- 将大 Key 拆分为小 Key。例如一个 String 拆分成多个 String
- 2、压缩
- 将 valuel 压缩后写入 redis,读取时解压后再使用。压缩算法可以是 gzip、snappy、lz4 等。通常情况下,一个压缩算法压缩率高、则解压耗时就长。需要对实际数据进行测试后,选择一个合适的算法
- 如果存储的是 JSON 字符串,可以考虑使用 MessagePack 进行序列化
- 3、集合类结构 hash、list、set
- 拆分:可以用 hash 取余、位掩码的方式决定放在哪个 Key 中
- 区分冷热:如榜单列表场景使用 zset,只缓存前 10 页数据,后续数据走 db
- 1、拆分
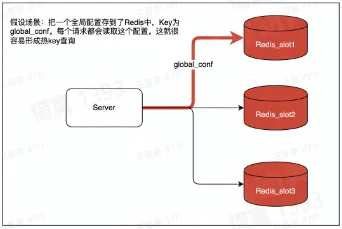
热 Key 的定义
- 用户访问一个 Key 的 QPS 特别高,导致 Server 实例出现 CPU 负载突增或者不均的情况
- 热 key 没有明确的标准,QPS 超过 500 就有可能被识别为热 Key
解决热 Key 的方法
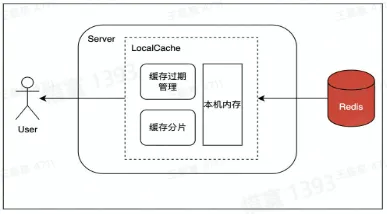
- 1、设置 Localcache
- 在访问 Redis 前,在业务服务侧设置 Localcache,降低访问 Redis 的 QPS。LocalCache 中缓存过期或未命中,则从 Redist 中将数据更新到 LocalCache。Java 的 Guava、Golang 的 Bigcache 就是这类 LocalCache
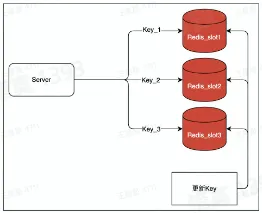
- 2、拆分
- 将 key : value 这一个热 Key 复制写入多份,例如 key1 : value,key2 : value,访问的时候访问多个 key,但 value 是同一个,以此将 qps 分散到不同实例上,降低负载。代价是,更新时需要更新多个 key,存在数据短暂不一致的风险
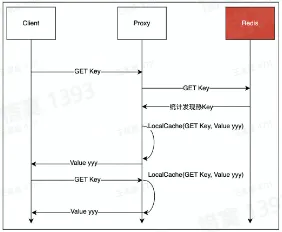
- 3、使用 Redis 代理的热 Key 承载能力
- 字节跳动的 Redis 访问代理就具备热 Key 承载能力。本质上是结合了“热 Key 发现”、“LocalCache”两个功能
- 1、设置 Localcache

慢查询场景
- 容易导致 redis 慢查询的操作
- 批量操作一次性传入过多的 key/value,如 mset/hmset/sadd/zadd 等 O(n)操作建议单批次不要超过 100,超过 100 之后性能下降明显
- Zset 大部分命令都是 O(log(n)),当大小超过 5k 以上时,简单的 zadd/zrem 也可能导致慢查询
- 操作的单个 vaue 过大,超过 10KB。也即,避免使用大 Key
- 对大 key 的 delete/expire 操作也可能导致慢查询,Redis4.0 之前不支持异步删除 unlink,大 key 删除会阻塞 Redis
缓存穿透、缓存雪崩
- 缓存穿透:热点数据查询绕过缓存,直接查询数据库
- 缓存雪崩:大量缓存同时过期
- 缓存穿透的危害
- 查询一个一定不存在的数据
- 通常不会缓存不存在的数据,这类查询请求都会直接打到 db,如果有系统 bug 或人为攻击,那么容易导致 db 响应慢甚至宕机
- 缓存过期时
- 在高并发场景下,一个热 key 如果过期,会有大量请求同时击穿至 db,容易影响 db 性能和稳定
- 同一时间有大量 key 集中过期时,也会导致大量请求落到 db 上,导致查询变慢,甚至出现 db 无法响应新的查询
- 查询一个一定不存在的数据
- 如何减少缓存穿透
- 缓存空值
- 如一个不存在的 userlD。这个 id 在缓存和数据库中都不存在。则可以缓存一个空值,下次再查缓存直接反空值
- 布隆过滤器
- 通过 bloom filter 算法来存储合法 Key,得益于该算法超高的压缩率,只需占用极小的空间就能存储大量 key 值
- 缓存空值
- 如何避免缓存雪崩
- 缓存空值
- 将缓存失效时间分散开,比如在原有的失效时间基础上增加一个随机值,例如不同 Key 过期时间可以设置为 10 分 1 秒过期,10 分 23 秒过期,10 分 8 秒过期。单位秒部分就是随机时间,这样过期时间就分散了
- 对于热点数据,过期时间尽量设置得长一些,冷门的数据可以相对设置过期时间短一些
- 使用缓存集群,避免单机宕机造成的缓存雪崩
- 缓存空值

