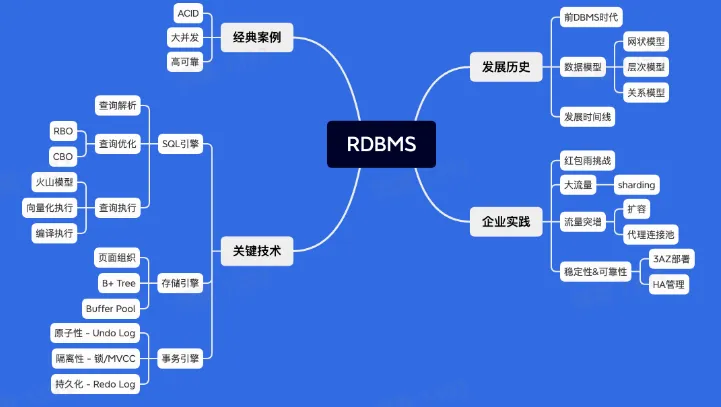
经典案例
- 从一场红包雨说起
- RDBMS 事务 ACID
- 事务(Transaction):是由一组 SQL 语句组成的一个程序执行单元(Unit),它需要满足 ACID 特性
- ACID:
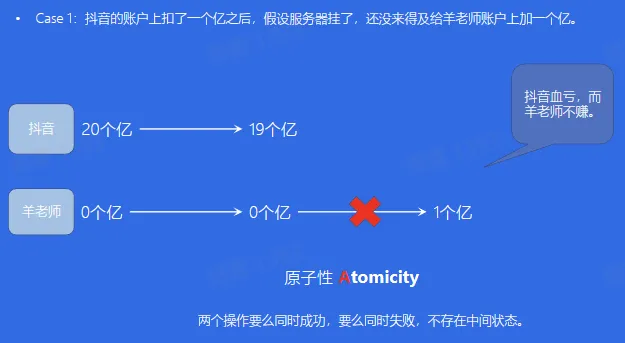
- 原子性(Atomicity):事务是一个不可再分割的工作单元,事务中的操作要么都发生,要么都不发生
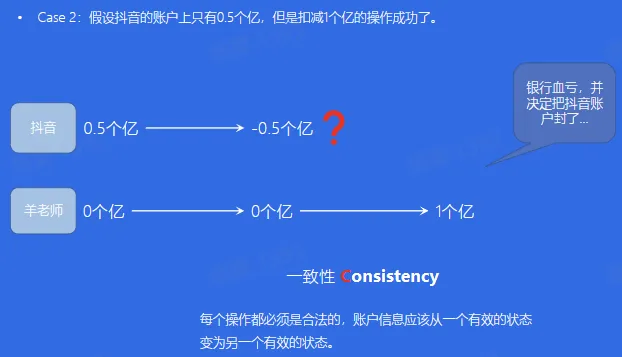
- 一致性(Consistency):数据库事务不能破坏关系数据的完整性以及业务逻辑上的一致性
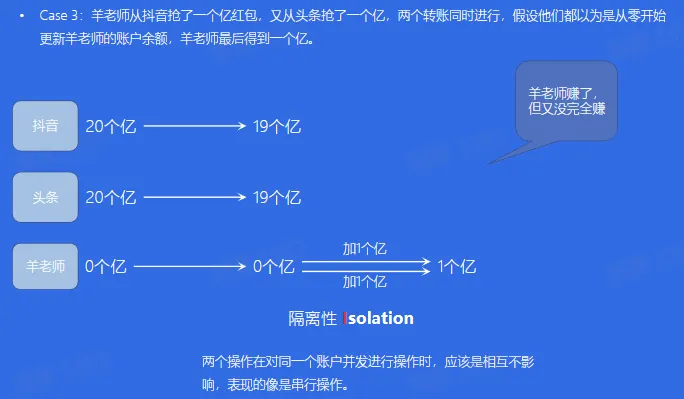
- 隔离性(Isolation):多个事务并发访问时,事务之间是隔离的,一个事务不应该影响其它事务运行效果
- 持久性(Durability):在事务完成以后,该事务所对数据库所做的更改便持久的保存在数据库之中,并不会被回滚
- 红包雨 与 ACID
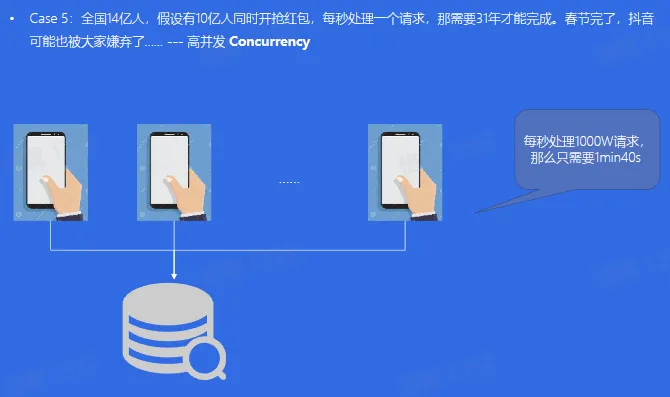
- 红包雨 与 高并发
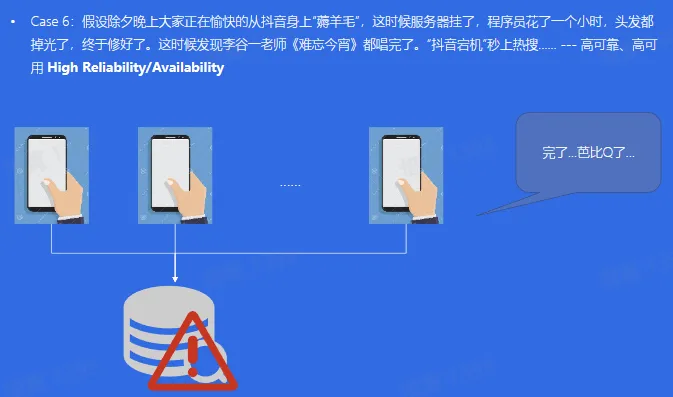
- 红包雨 与 高可靠
- 事务(Transaction):是由一组 SQL 语句组成的一个程序执行单元(Unit),它需要满足 ACID 特性



发展历史
前 DBMS 时代
- 人工管理
- 在现代计算机发明出来以前,通过人工的方式进行数据记录和管理
- 文件系统
- 1950s,现代计算机的雏形基本出现。1956 年 IBM 发布了第一个磁盘驱动器–Model 305 RAMAC,从此数据存储进入硬盘时代。在这个阶段,数据管理直接通过文件系统来实现
DBMS 时代
- 1960s,传统的文件系统已经不能满足人们的需要,数据库管理系统(DBMS)应运而生
- DBMS:按照某种数据模型来组织、存储和管理数据的仓库
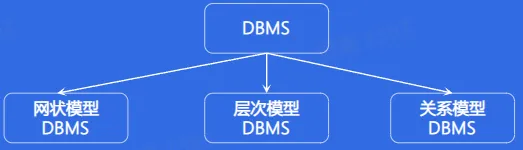
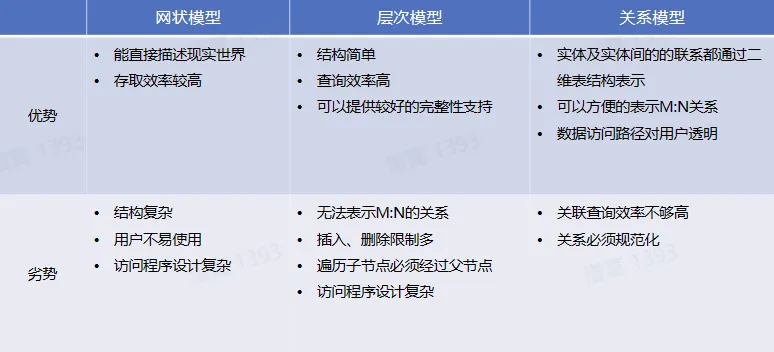
- 所以通常按照数据模型的特点将传统数据库系统分成网状数据库、层次数据库和关系数据库三类
DBMS 数据模型
- 网状模型
- 网状数据库所基于的网状数据模型建立的数据之间的联系,能反映现实世界中信息的关联,是许多空间对象的自然表达形式
- 1964 年,世界上第一个数据库系统一集成数据存储(Integrated Data Storage,IDS)诞生于通用电气公司。1DS 是世界上第一个网状数据库,奠定了数据库发展的基础,在当时得到了广泛的应用。在 1970s 网状数据库系统十分流行,在数据库系统产品中占据主导地位
- 层次模型
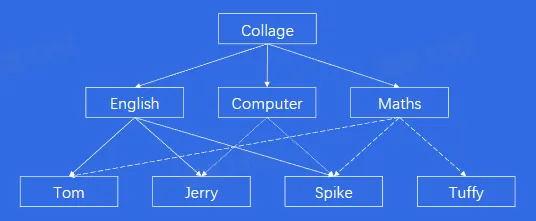
- 1968 年,世界上第一个层次数据库一信息管理系统(Information Management System,IMS)诞生于于 IBM 公司,这也是世界上第一个大型商用的数据库系统。层次数据模型,即使用树形结构来描述实体及其之间关系的数据模型
- 关系模型
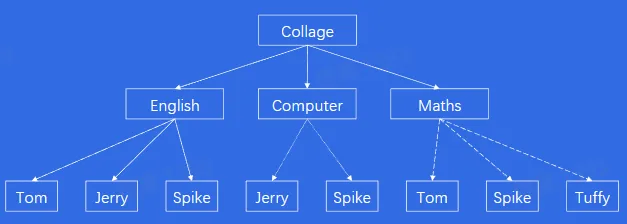
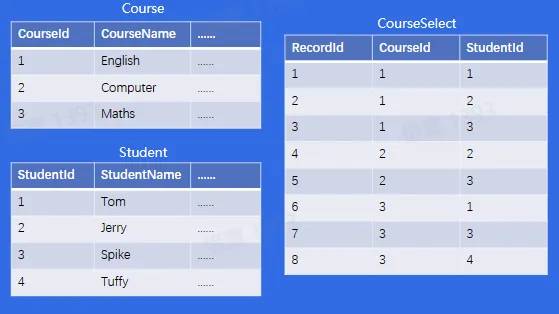
- 1970 年,IBM 的研究员 E.F.Codd 博士发表了一篇名为“A Relational Model of Data for large Shared Data Banks”的论文,提出了关系模型的概念,奠定了关系模型的理论基础。1979 年 Oracle 首次将关系型数据库商业化,后续 DB2,SAP Sysbase ASE,and Informix 等知名数据库产品也纷纷面世
- 优劣势
SQL 语言
- 1974 年 IBM 的 Ray Boycei 和 Don Chamberlin 将 Codd 关系数据库的 12 条准则的数学定义以简单的关键字语法表现出来,里程碑式地提出了 SQL(Structured Query Language)语言
- 语法风格接近自然语言
- 高度非过程化
- 面向集合的操作方式
- 语言简洁,易学易用

历史回顾

关键技术
一条 SQL 的一生
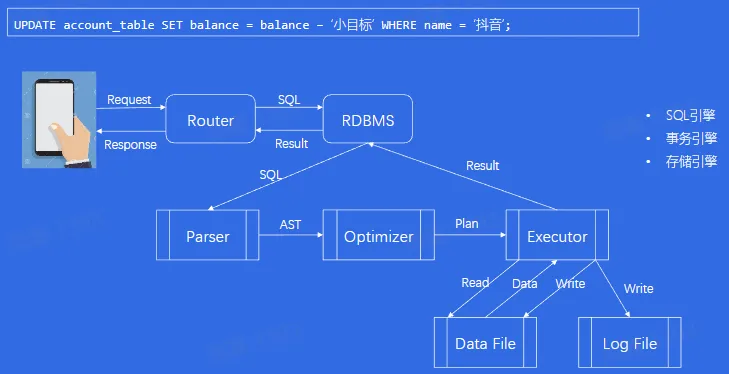
SQL 引擎
- Parser
- 解析器(Parser)一般分为词法分析(Lexical analysis)、语法分析(Syntax analysis))、语义分析(Semantic analyzer)等步骤
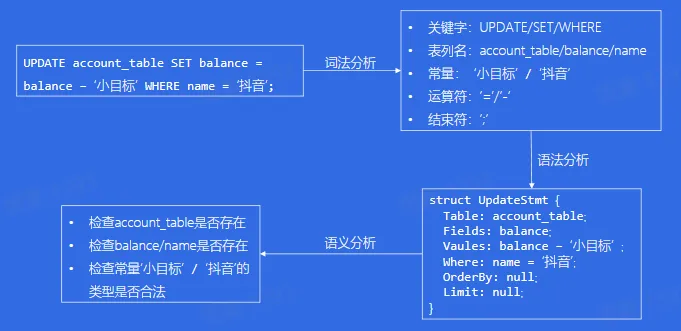
- Optimizer
- 为什么需要一个优化器(Optimizer)?
- 基于规则的优化(RBO Rule Base Optimizer)
- 条件化简
- 表连接优化
- 总是小表先进行连接
- Scan 优化
- 唯一索引
- 普通索引
- 全表扫描
- 数据库索引:是数据库管理系统中辅助数据结构,以协助快速查询、更新数据库表中数据。目前数据库中最常用的索引是通过 B+树实现的
- 条件化简
- 基于代价的优化(CBO Cost Base Optimizer)
- 一个查询有多种执行方案,CBO 会选择其中代价最低的方案去真正的执行
- 什么是代价?
- 为什么需要一个优化器(Optimizer)?
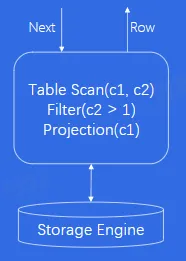
- Executor
- 火山模型
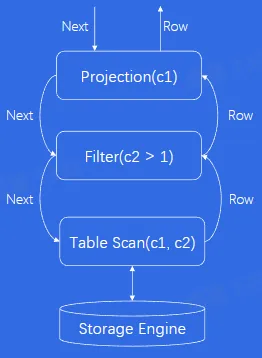
- 每个 Operator 调用 Next 操作,访问下层 Operator,获得下层 Operator 返回的一行数据,经过计算之后,将这行数据返回给上层
- 优点:
- 每个算子独立抽象实现,相互之间没有耦合,逻辑结构简单
- 缺点:
- 每计算一条数据有多次函数调用开销,导致 CPU 效率不高
- 向量化
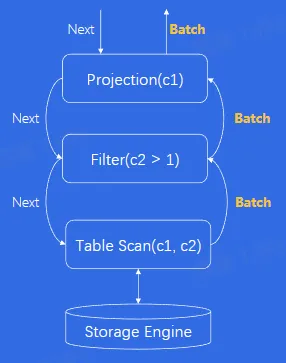
- 每个 ○perator 每次操作计算的不再是一行数据,而是一批数据(Batch N 行数据),计算完成后向上层算子返回一个 Batch
- 优点:
- 函数调用次数降低为 1/N
- CPU cache 命中率更高
- 可以利用 CPU 提供的 SIMD(Single Instruction Multi Data)机制
- 编译执行
- 将所有的操作封装到一个函数里面,函数调用的代价也能大幅度降低
- 用户 SQL 干变万化怎么办?难道要穷举用户的所有 SQL,给每一个 SQL 都预先写好一个执行函数吗?
- 火山模型
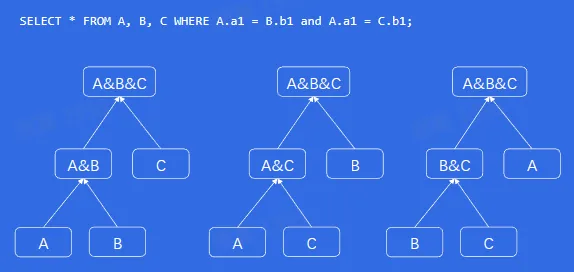


存储引擎
- InnoDB
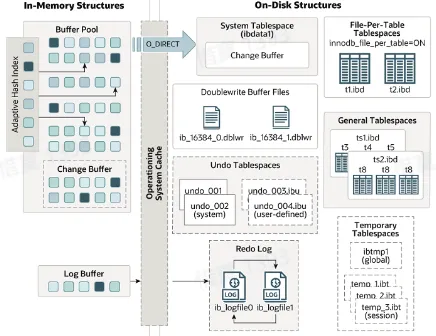
- In-Memory:
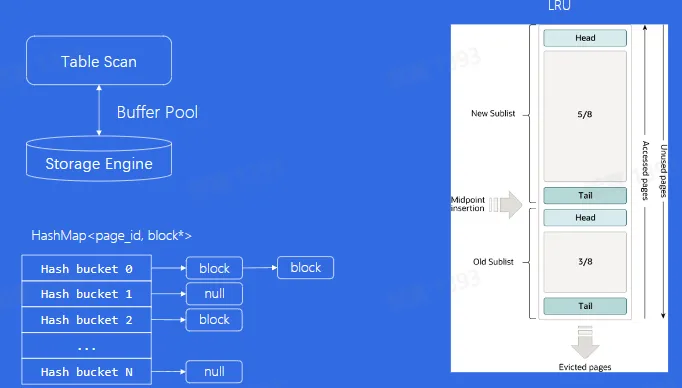
- Buffer Pool
- Change Buffer
- Adaptive Hash Index
- Log Buffer
- On-Disk:
- System Tablespace(ibdata1)
- General Tablespaces(xxx.ibd)
- Undo Tablespaces(xxx.ibu)
- Temporary Tablespaces(xxx.ibt)
- Redo Log(ib_logfileN)
- Buffer Pool
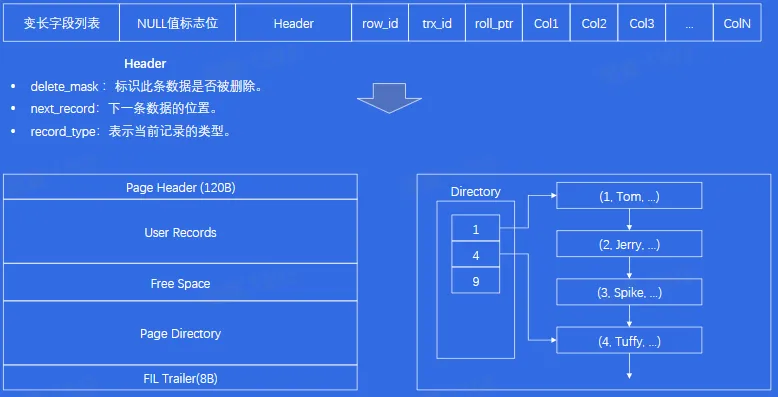
- Page
- B+ Tree
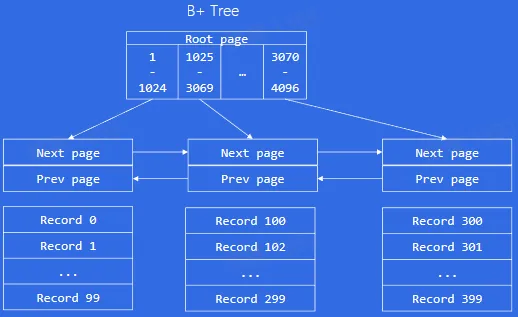
- 页面内:
- 页目录中使用二分法快速定位到对应的槽,然后再遍历该槽对应分组中的记录即可快速找到指定的记录。
- 从根到叶:
- 中间节点存储
- 点查:
- Select * from table wehre id = 2000;
- 范围查询:
- Select * from table wehre id > 2000;

事务引擎
- Atomicity 与 Undo Log
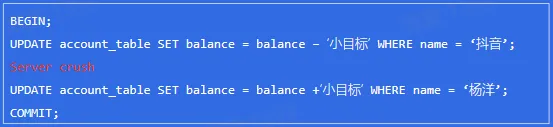
- 如何将数据库回退到修改之前的状态?
- Undo Log
- Undo Log 是逻辑日志,记录的是数据的增量变化。利用 Undo Log 可以进行事务回滚,从而保证事务的原子性。同时也实现了多版本并发控制(MVCC),解决读写冲突和一致性读的问题
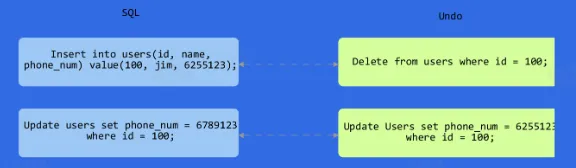
- Undo Log
- Isolation 与 锁
- 前情提要:羊老师从抖音抢了一个亿红包,又从头条抢了一个亿。抖音和头条都要往羊老师的账户转一个亿,如果两个操作同时进行,发生冲突怎么办?

- Isolation 与 MVCC
- MVCC 的意义:
- 读写互补阻塞
- 降低死锁概率
- 实现一致性读
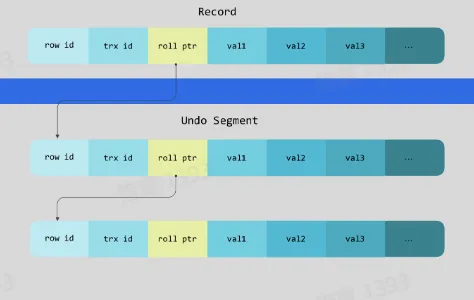
- Undo Log 在 MVCC 的作用:
- 每个事务有一个单增的事务 ID
- 数据页的行记录中包含了 DB_ROW_ID,DB_TRX_ID,DB_ROLL_PTR
- DB_ROLL_PTR 将数据行的所有快照记录都通过链表的结构串联了起来
- Durability 与 Redo Log
- 如何保证事务结束后,对数据的修改永久的保存?
- 方案一:事务提交前页面写盘

- 问题:随机 IO、写放大
- 方案二:WAL(Write-ahead logging)
- redo log 是物理日志,记录的是页面的变化,它的作用是保证事务持久化。如果数据写入磁盘前发生故障,重启 MySQL 后会根据 redo log 重做
企业实践
春节红包雨挑战

大流量-Sharding
- 问题背景
- 单节点写容易成为瓶颈
- 单机数据容量上限
- 解决方案
- 业务数据进行水平拆分
- 代理层进行分片路由
- 实施效果
- 数据库写入能力扩展
- 数据库容量线性扩展
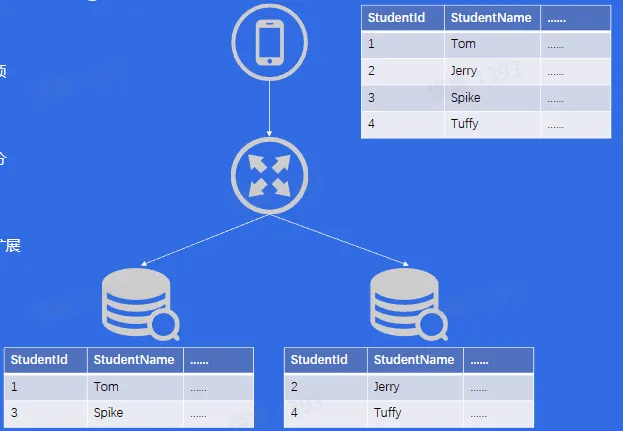
流量突增
- 扩容
- 问题背景
- 活动流量上涨
- 集群性能不满足要求
- 解决方案
- 扩容 DB 物理节点数量
- 利用影子表进行压测
- 实施效果
- 数据库集群提供更高的吞吐
- 保证集群可以承担预期流量
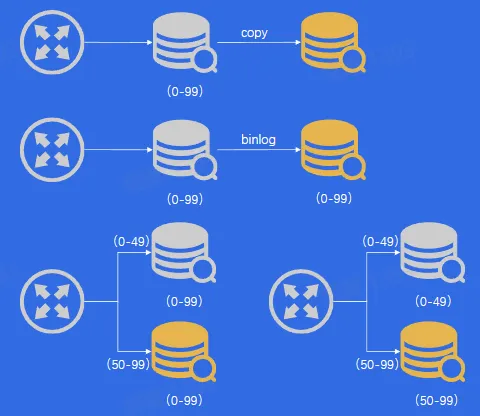
- 问题背景
- 代理连接池
- 问题背景
- 突增流量导致大量建联
- 大量建联导致负载变大,延时上升
- 解决方案
- 业务侧预热连接池
- 代理则预热连接池
- 代理侧则支持连接队列
- 实施效果
- 避免 DB 被突增流量打死
- 避免代理和 DB 被大量建联打死
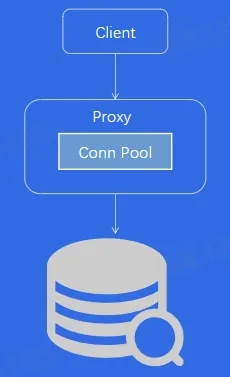
- 问题背景
稳定性&可靠性
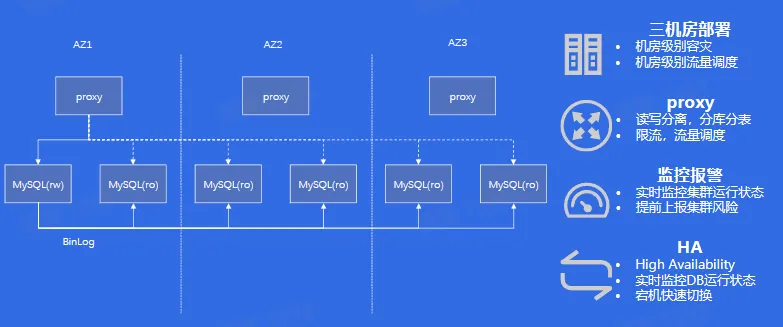
- 3AZ 高可用
- HA 管理
- 问题背景
- db 所在机器异常宕机
- db 节点异常宕机
- 解决方案
- ha 服务监管、切换宕机节点
- 代理支持配置热加载
- 代理自动屏蔽宕机读节点
- 实施效果
- 读节点宕机秒级恢复
- 写节点宕机 30s 内恢复服务
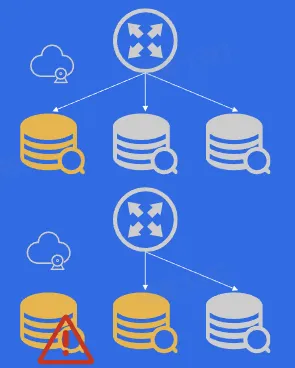
- 问题背景