数据库基本概念
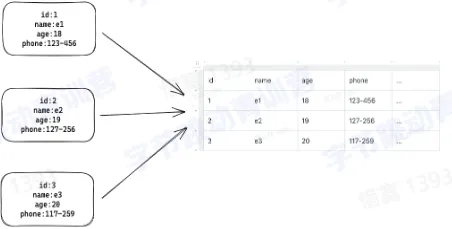
数据库是结构化信息或数据的有序集合,一般以电子形式存储在计算机系统中。通常由数据库管理系统(DBMS)来控制。在现实中,数据、DBMS 及关联应用一起被称为数据库系统,通常简称为数据库
一个简单的例子
- 数据解析整理成有序集合
- 可以通过查询语言获取想要的信息
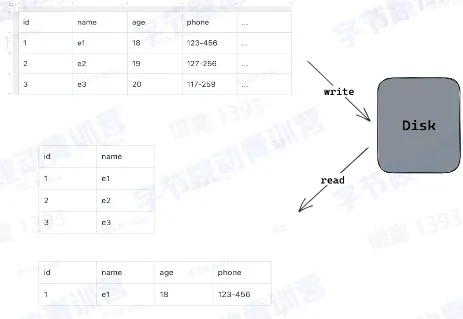
数据库的类型
- 数据库有很多种,至于各种数据库孰优孰劣,主要取决于企业希望如何使用数据
- 关系数据库:关系型数据库是把数据以表的形式进行储存,然后再各个表之间建立关系,通过这些表之间的关系来操作不同表之间的数据
- 非关系数据库 : NoSQL 或非关系数据库,支持存储和操作非结构化及半结构化数据。相比于关系型数据库,NoSQL 没有固定的表结构,且数据之间不存在表与表之间的关系,数据之间可以是独立的。NoSQL 的关键是它们放弃了传统关系型数据库的强事务保证和关系模型,通过所谓最终一致性和非关系数据模型(例如键值对,图,文档)来提高 Web 应用所注重的高可用性和可扩展性
- 单机数据库:在一台计算机上完成数据的存储和查询的数据库系统
- 分布式数据库 : 分布式数据库由位于不同站点的两个或多个文件组成。数据库可以存储在多台计算机上,位于同一个物理位置,或分散在不同的网络上
- OLTP 数据库 : OLTP(Online transactional processing)数据库是一种高速分析数据库,专为多个用户执行大量事务而设计
- OLAP 数据库:OLAP (Online analytical processing) 数据库旨在同时分析多个数据维度,帮助团队更好地理解其数据中的复杂关系
OLAP 数据库
- 大量数据的读写,PB 级别的存储
- 多维分析,复杂的聚合函数
- 窗口函数,自定义 UDF (User Define Fucntion)
- 离线/实时分析

SQL
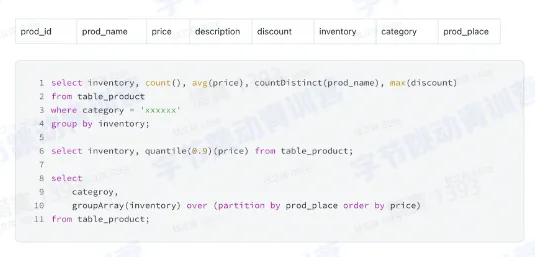
- 一种编程语言,目前几乎所有的关系数据库都使用 SQL (Structured Query Language ) 编程语言来查询、操作和定义数据,进行数据访问控制
- SQL 的结构
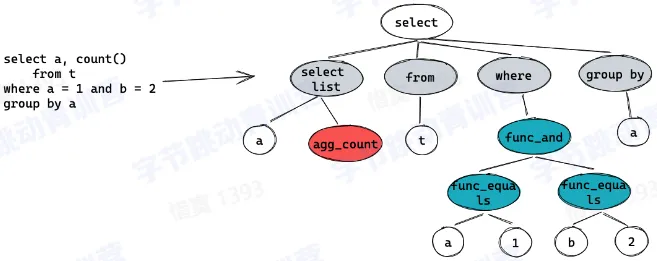
- 一个简单的 SQL 查询包含 SELECT 关键词。星号(“*“)也可以用来指定查询应当返回查询表所有字段,可选的关键词和子句
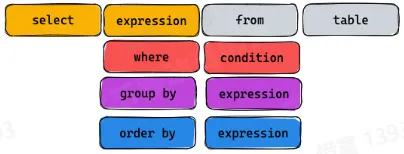
FROM子句指定了选择的数据表。FROM子句也可以包含JOIN二层子句来为数据表的连接设置规则WHERE子句后接一个比较谓词以限制返回的行。WHERE子句仅保留返回结果里使得比较谓词的值为 True 的行GROUP BY子句用于将若干含有相同值的行合并。GROUP BY通常与 SQL 聚合函数连用,或者用于清除数据重复的行。GROUP BY子句要用在WHERE子句之后HAVING子句后接一个谓词来过滤从GROUP BY子句中获得的结果,由于其作用于GROUP BY子句之上,所以聚合函数也可以放到其谓词中ORDER BY子句指明将哪个字段用作排序关键字,以及排序顺序(升序/降序),如果无此子句,那么返回结果的顺序不能保证有序
- SQL 的用途
- 定义数据模型
- 读写数据库数据
- 定义数据模型
- SQL 的优点
- 标准化,ISO 和 ANSI 是长期建立使用的 SQL 数据库标准
- 高度非过程化,用 SQL 进行数据操作,用户只需提出“做什么”,而不必指明“怎么做”,因此用户无须了解存取路径,存取路径的选择以及 SQL 语句的操作过程由系统自动完成。这不但大大减轻了用户负担,而且有利于提高数据独立性
- 以同一种语法结构提供两种使用方式,用户可以在终端上直接输入 SQL 命令对数据库进行操作。作为嵌入式语言,SQL 语句能够嵌入到高级语言(如 C、C#、JAVA)程序中,供程序员设计程序时使用。而在两种不同的使用方式下,SQL 的语法结构基本上是一致的
- 语言简洁,易学易用:SQL 功能极强,但由于设计巧妙,语言十分简洁,完成数据定义、数据操纵、数据控制的核心功能只用了 9 个动词:CREATE、ALTER、DROP、SELECT、INSERT、UPDATE、DELETE、GRANT、REVOKE。且 SQL 语言语法简单,接近英语口语,因此容易学习,也容易使用

数据库的架构
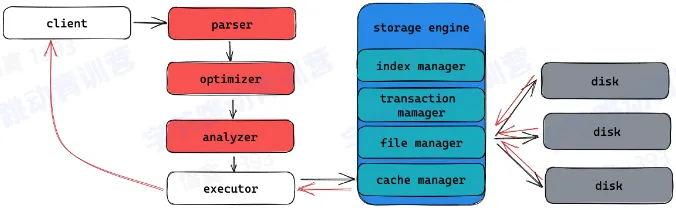
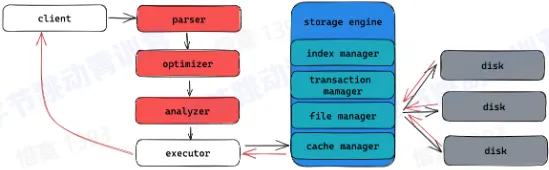
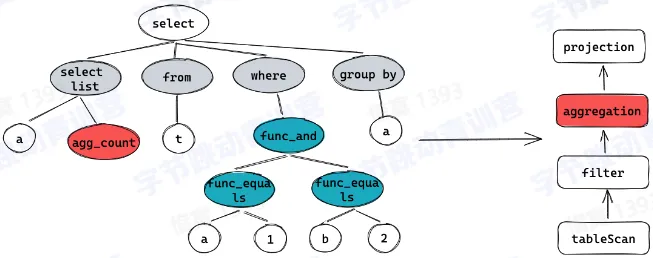
- SQL 的执行
- Parser:词法分析,语法分析,生成 AST 树 (Abstract syntax tree)
- Analyzer:变量绑定、类型推导、语义检查、安全、权限检查、完整性检查等,为生成计划做准备
- 例如:
- 判断 a,b 是不是类型正确
- a,b 是不是来自表 t
- group by 字段是否合法,是否存在聚合函数
- 例如:
- Optimizer:为查询生成性能最优的执行计划,进行代价评估
- Executor:将执行计划翻译成可执行的物理计划并驱动其执行
- Parser:词法分析,语法分析,生成 AST 树 (Abstract syntax tree)
- 存储引擎
- 管理内存数据结构
- 索引
- 内存数据
- 缓存
- Query cache
- Data cache
- Index cache
- 管理磁盘数据
- 磁盘数据的文件格式
- 磁盘数据的增删查改
- 读写算子
- 数据写入逻辑
- 数据读取逻辑
- 如何存储数据?
- 是否可以并发处理
- 是否可以构建索引
- 行存、列存或者行列混合存储
- 如何读写数据?
- 读多写少
- 读少写多
- 点查场景
- 分析型场景
- 管理内存数据结构
列式存储
列式存储的优点
- 数据压缩
- 数据压缩可以使读的数据量更少,在 IO 密集型计算中获得大的性能优势
- 相同类型压缩效率更高
- 排序之后压缩效率更高
- 可以针对不同类型使用不同的压缩算法
- 几种常见的压缩算法

- LZ4
- (5,4) 代表向前 5 个 byte,匹配到的内容长度有 4,即”bcde”是一个重复
- 重复项越多或者越长,压缩率就会越高

- Run-length encoding
- 压缩重复的数据
- 可以在压缩数据上直接计算

- Delta encoding
- 将数据存储为连续数据之间的差异,而不是直接存储数据本身
- 特定算子也能直接在压缩数据上计算
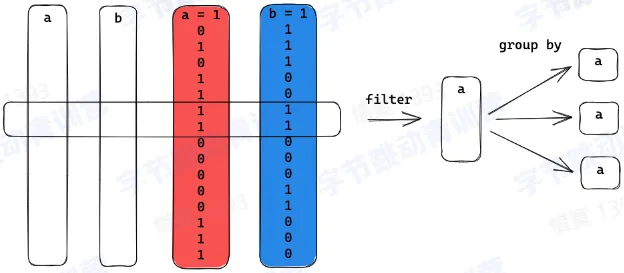
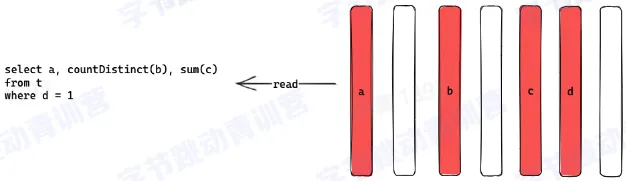
- 数据选择
- 可以选择特定的列做计算而不是读所有列
- 对聚合计算友好
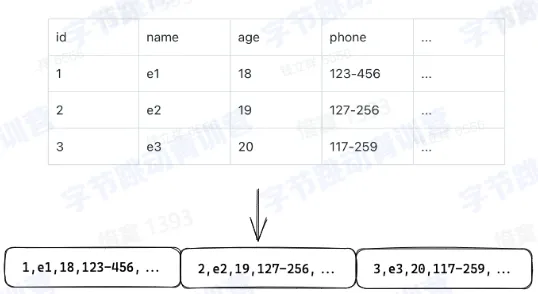
- 延迟物化
- 物化:将列数据转换为可以被计算或者输出的行数据或者内存数据结果的过程,物化后的数据通常可以用来做数据过滤,聚合计算,Join
- 延迟物化:尽可能推迟物化操作的发生
- 缓存友好
- CPU / 内存带宽友好
- 可以利用到执行计划和算子的优化,例如 filter
- 保留直接在压缩列做计算的机会
- 物化:将列数据转换为可以被计算或者输出的行数据或者内存数据结果的过程,物化后的数据通常可以用来做数据过滤,聚合计算,Join
- 向量化
- SIMD (single instruction multiple data),对于现代多核 CPU,其都有能力用一条指令执行多条数据
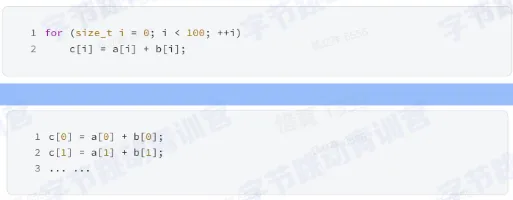
- 如果这时候 CPU 也可以并行的计算我们写的代码,那么理论上我们的处理速度就会是之前代码的 100 倍,幸运的是 SIMD 指令就是完成这样的工作的,用 SIMD 指令完成这样代码设计和执行就叫做向量化
- 指令集
- SIMD 程序使用的指令集有 SSE 和 AVX 系列,AVX 有 AVX-256 和 AVX-512,SSE 提供 128-bits 的寄存器,AVX-256 提供 256-bits,AVX-512 提供 512bits 的寄存器
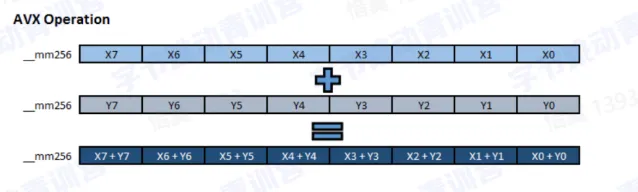
- 数据格式要求
- 需要处理多个数据,因此数据需要是连续内存
- 需要明确数据类型
- 执行模型
- 数据需要按批读取
- 函数的调用需要明确数据类型

- 列存数据库适合设计出这样的执行模型,从而使用向量化技术
- 按列读取
- 每种列类型定义数据读写逻辑
- 函数按列类型处理
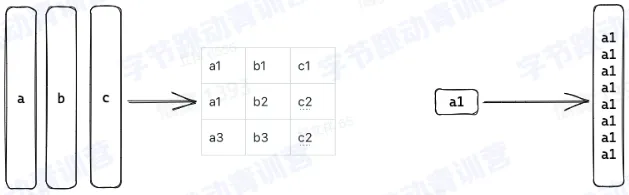
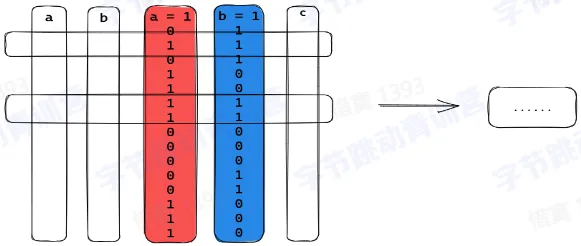
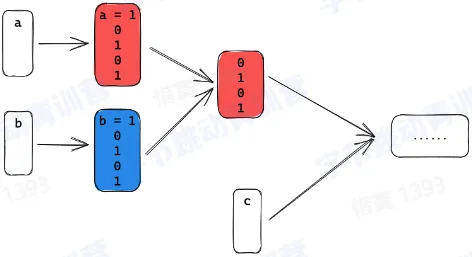
行存 VS 列存

ClickHouse 存储设计
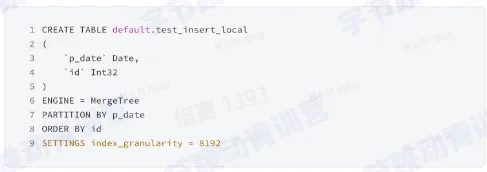
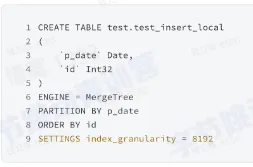
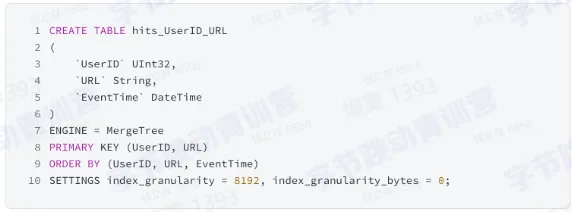
表定义和结构

集群架构
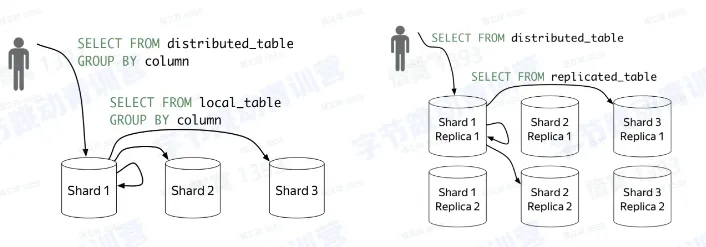
引擎架构
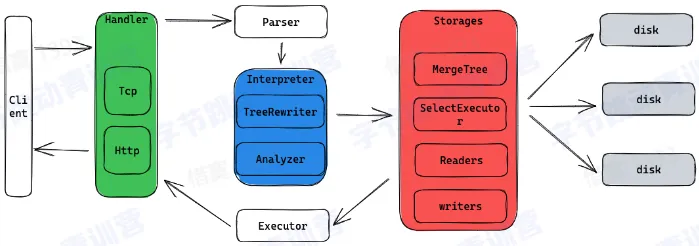
存储架构
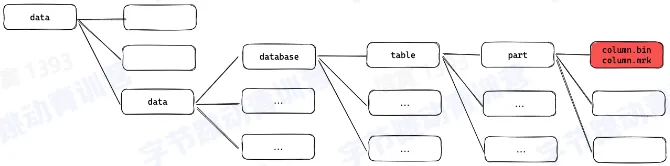
- 文件组织
- part 和 partition
- part 是物理文件夹的名字
- partition 是逻辑结构
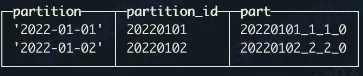
- part 和 column
- 每个 column 都是一个文件
- 所有的 column 文件都在自己的 part 文件夹下
- column 和 index
- 一个 part 有一个主键索引
- 每个 column 都有列索引
索引设计
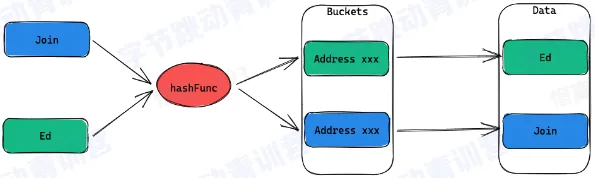
Hash index
- 将输入的 key 通过一个 HashFunction 映射到一组 bucket 上
- 每个 bucket 都包含一个指向一条记录的地址
- 哈希索引在查找的时候只适用于等值比较
B-Tree
- 数据写入是有序的,支持增删查改
- 每个节点有多个孩子节点
- 每个节点都按照升序排列 key 值
- 每个 key 有两个指向左右孩子节点的引用
- 左孩子节点保存的 key 都小于当前 key
- 右孩子节点的保存的 key 都大于当前 key
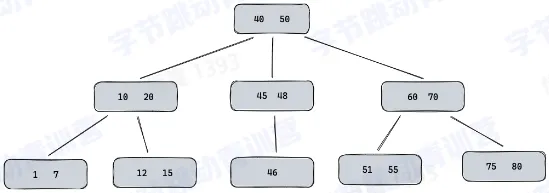
B+Tree
- 所有的数据都存储在叶子节点,非叶子节点只保存 key 值
- 叶子节点维护到相邻叶子节点的引用
- 可以通过 key 值做二分查找,也可以通过叶子节点做顺序访问
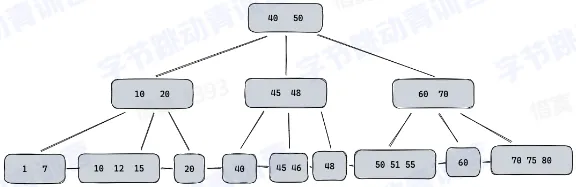
对于大数据量,B(B+)-Tree 深度太高
索引数据量太大,多个列如何平衡查询和存储——LSM-Tree
OLAP 场景写入量非常大,如何优化写入
Log-structured merge-tree(LSM tree)是一种为大吞吐写入场景而设计的数据结构
- 着重优化顺序写入
- 主要数据结构
- SSTables
- Memtable
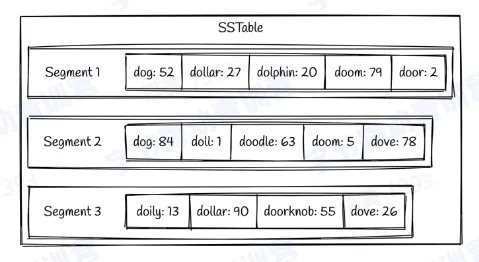
SSTables
- Key 按顺序存储到文件中,称为 segment
- 包含多个 segment
- 每个 segment 写入磁盘后都是不可更改的,新加的数据只能生成新的 segment
Memtable
- 在内存中的数据保存在 memtable 中,大多数实现都是一颗 Binary search tree
- 当 memtable 存储的数据到达一定的阈值的时候,就会按顺序写入到磁盘
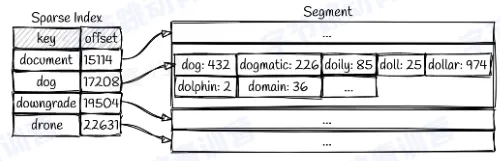
数据查询
- 需要从最新的 segment 开始遍历每个 key
- 也可以为每个 segment 建一个索引,例如
Compaction(合并)
- Compaction 指将多个 segments 合并成一个 segments 的过程
- 一般是有一个后台线程完成
- 不同的 segments 写入新的 segment 的时候也是需要排序,形成新的 segment 之后,旧的 segment 文件就会被删除
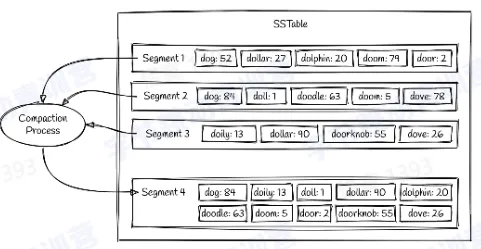
- Compaction 指将多个 segments 合并成一个 segments 的过程
索引实现
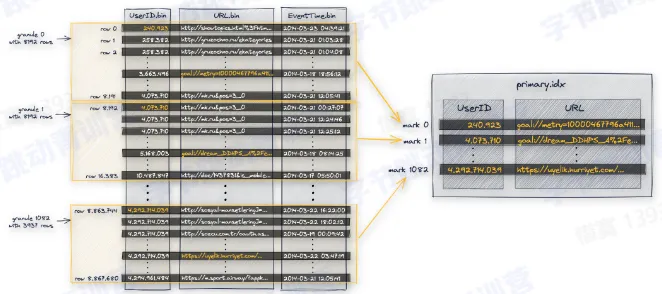
- 主键索引
- 数据按照主键顺序依次做排序
- 首先按照 UserID 做排序
- 再按照 URL 排序
- 最后是 EventTime

- 数据被划分成 granule
- granule 是最小的数据读取单元
- 不同的 granulas 可以并行读取
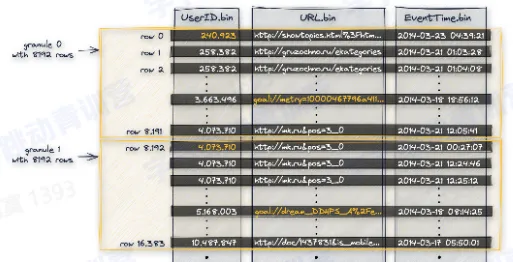
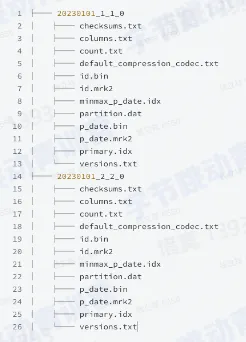
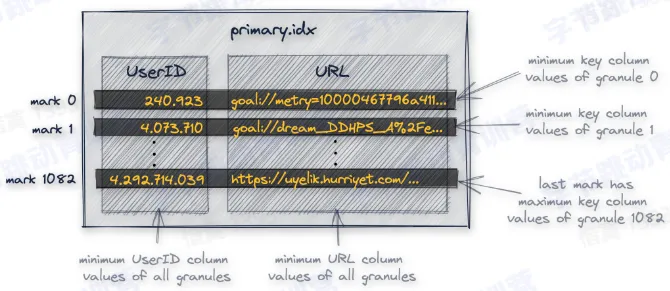
- 每个 granule 都对应 primary.idx 里面的一行
- 默认每 8192 行记录主键的一行值,primary.idx 需要被全部加载到内存里面
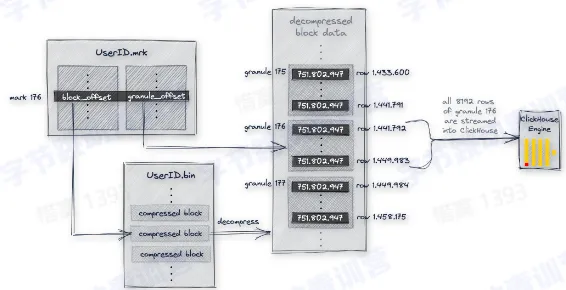
- 里面保存的每一行数据被称为一个 index mark
- 每个列都有这样一个 mark 文件
- mark 文件保存的是每个 granule 的物理地址
- 每一列都有一个自己的 mark 文件
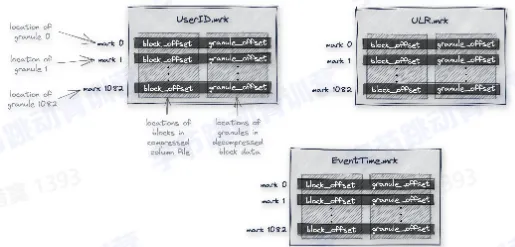
- mark 文件里面的每一行存储两个地址
- 第一个地址称为 block_offset,用于定位一个 granule 的压缩数据在物理文件中的位置,压缩数据会以一个 block 为单位解压到内存中
- 第二个地址称为 granule_offset,用于定位一个 granule 在解压之后的 block 中的位置
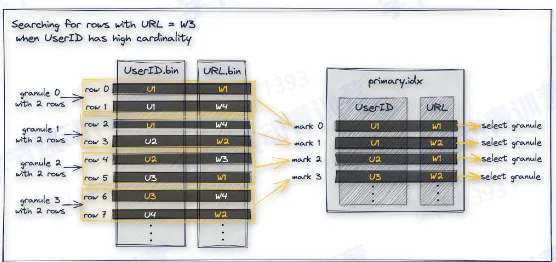
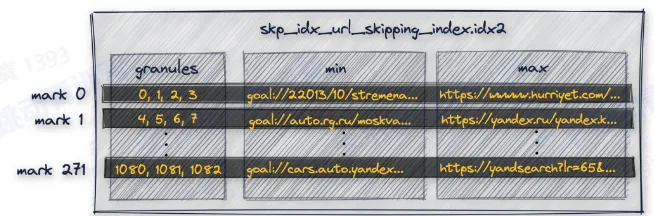
- 缺陷:数据按照 key 的顺序做排序,因此只有第一个 key 的过滤效果好,后面的 key 过滤效果依赖第一个 key 的基数大小
查询优化
- secondary index:在 URL 列上构建二级索引
- 构建多个主键索引
- 再建一个表
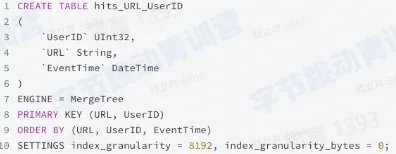
- 数据需要同步两份
- 查询需要用户判断查哪张表
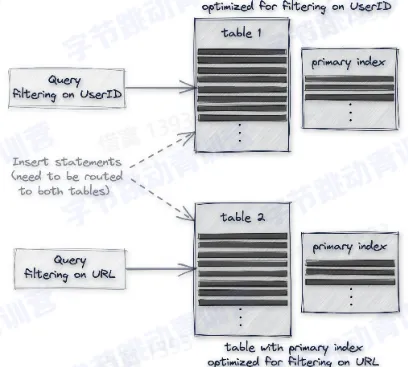
- 建一个物化视图
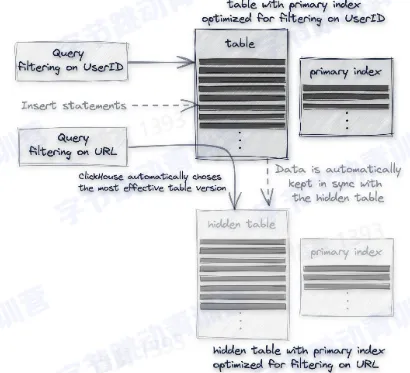
- 物化视图:可以通过 select 查询将一个表的数据写入一张隐式表
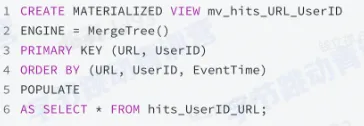
- 数据自动同步到隐式表
- 查询需要用户判断查哪张表
- 使用 Projection
- projection:类似于物化试图,但是不是将数据写入新的表,而是存储在原始表中,以一个列文件的形式存在
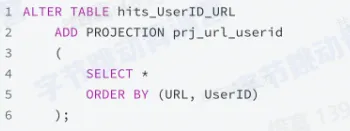
- 数据自动同步到隐式表
- 查询自动路由到最优的表
- 小结
- 主键包含的数据顺序写入
- 主键构造一个主键索引
- 每个列构建一个稀疏索引
- 通过 mark 的选择让主键索引可以定位到每一列的索引
- 可以通过多种手段优化非主键列的索引
- 再建一个表
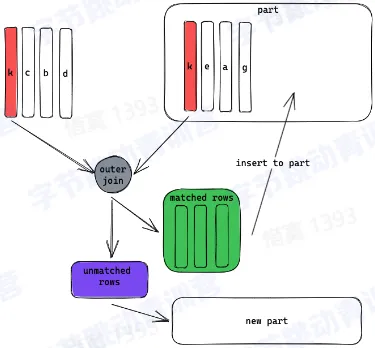
数据合并
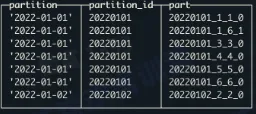
- 一个 part 内的数据是有序的
- 不同 part 之间的数据是无序的
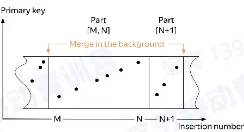
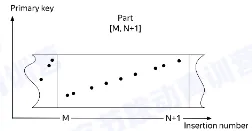
- 数据合并是将多个 part 合并成一起的过程
- part 的合并发生在一个分区内
- 数据的可见性
- 数据合并过程中,未被合并的数据对查询可见
- 数据合并完成后,新 part 可见,被合并的 part 被标记删除


数据查询
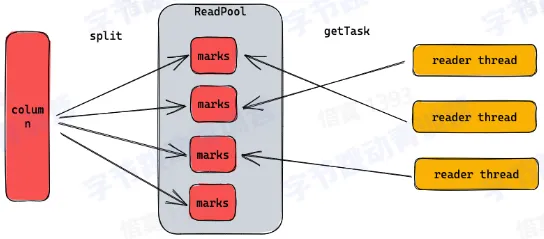
- 通过主键找到需要读的 mark
- 切分 marks,然后并发的调度 reader
- Reader 通过 mark block_offset 得到需要读的数据文件的偏移量
- Reader 通过 mark granule_offset 得到解压之后数据的偏移量
- 构建列式 filter 做数据过滤

ClickHouse 应用场景
- 大宽表存储和查询
- 大宽表查询
- 可以建非常多的列
- 可以增加,删除,清空每一列的数据
- 查询的时候引擎可以快速选择需要的列
- 可以将列涉及到的过滤条件下推到存储层从而加速查询

- 动态表结构
- map 中的每个 key 都是一列
- map 中的每一列都可以单独的查询
- 使用方式同普通列,可以做任何计算

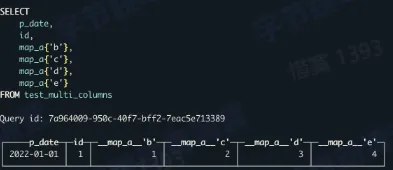
- 大宽表查询
- 离线数据分析
- 数据导入
- 数据可以通过 spark 生成 clickhouse 格式的文件
- 导入到 hdfs 上由 hive2ch 导入工具完成数据导入
- 数据直接导入到各个物理节点
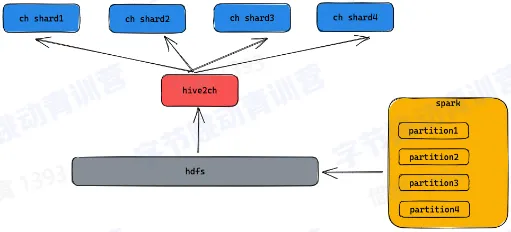
- 数据按列导入
- 保证查询可以及时访问已有数据
- 可以按需加载需要的列
- 数据导入
- 实时数据分析
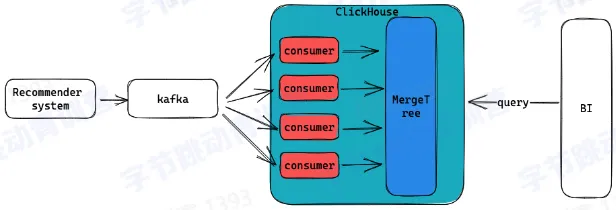
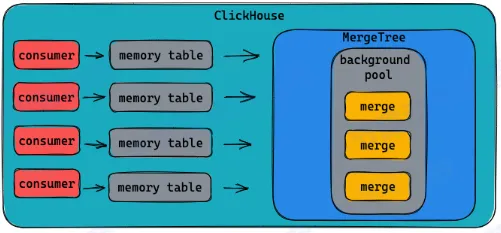
- 使用 memory table 减少 parts 数量
- 数据先缓存在内存中
- 到达一定阈值再写到磁盘
- 复杂类型查询
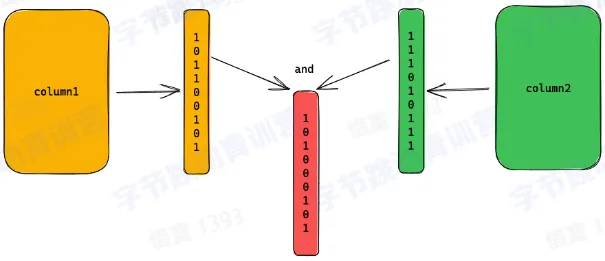
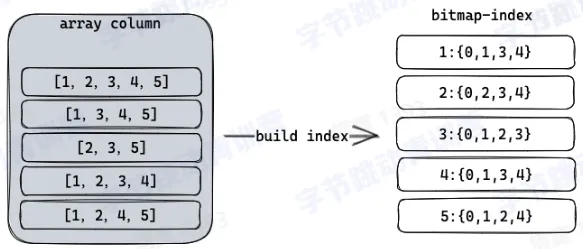
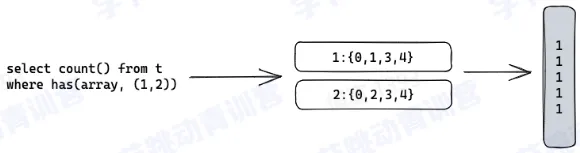
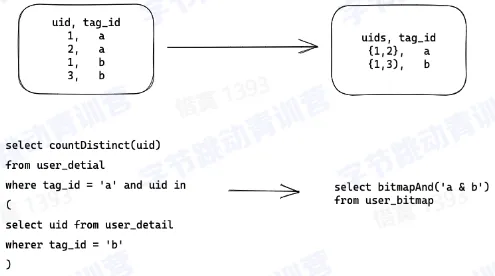
- bitmap 索引
- 构建
- 查询
- 构建
- bitmap64 类型
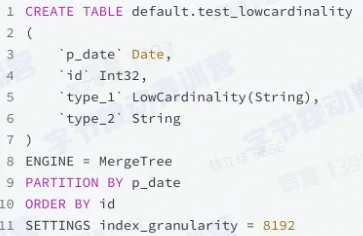
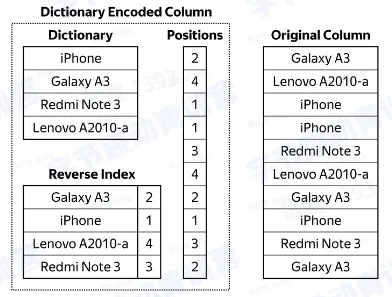
- lowcardinality
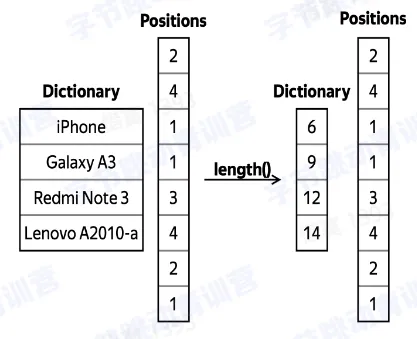
- 对于低基数列使用字典编码
- 减少数据存储和读写的 IO 使用
- 可以做运行时的压缩数据过滤
- bitmap 索引
总结
- ClickHouse 是标准的列存结构
- 存储设计是 LSM-Tree 架构
- 使用稀疏索引加速查询
- 每个列都有丰富的压缩算法和索引结构
- 基于列存设计的高效的数据处理逻辑

